
Format Message Modeling
Contents
Format Message Modeling#
The Netzob Description Language (ZDL) is the API exposed by the Netzob library to model data structures employed in communication protocols. This textual language has been designed in order to be easily understandable by a human. It enables the user to describe a protocol through dedicated *.zdl files, which are independent of the API and core of the library. The ZDL language has been designed with attention to its expressiveness. In this chapter, firstly, the main concepts of the ZDL language are presented, then its expressiveness in terms of data types, constraints and relationships are explained.
Format Message Modeling Concepts#
Definitions: Symbol, Field, Variable#
In the Netzob library, the set of valid messages and their formats are represented through symbols. A symbol represents all the messages that share a similar objective from a protocol perspective. For example, the HTTP_GET symbol would describe any HTTP request with the GET method being set. A symbol can be specialized into a context-valid message and a message can be abstracted into a symbol.
A field describes a chunk of the symbol and is defined by a definition domain, representing the set of values the field handles. To support complex domains, a definition domain is represented by a tree where each vertex is a Variable. There are three kinds of variables:
Data variables, which describes data whose value is of a given type. Various types are provided with the library, such as String, Integer, Raw and BitArray.
Relationship variables, which make it possible to model a relationship between a variable and a list of variables or fields. Besides, relationships can be done between fields of different symbols, thus making it possible to model both intra-symbol relationships and inter-symbol relationships.
Node variables, which accept one or more children variables.
Node variables can be used to construct complex definition domains, such as:
Aggregate node variable, which can be used to model a concatenation of variables.
Alternate node variable, which can be used to model an alternative of multiple variables.
Repeat node variable, which can be used to model a repetition of a variable.
Optional node variable, which can be used to model a variable that may or may not be present.
As an illustration of these concepts, the following figure presents the definition of a Symbol structured with three Fields. The first field contains an alternative between String Data with a constant string and Integer Data with a constant value. The second field is String Data with a variable length string. The third field depicts an Integer whose value is the size of the second string.
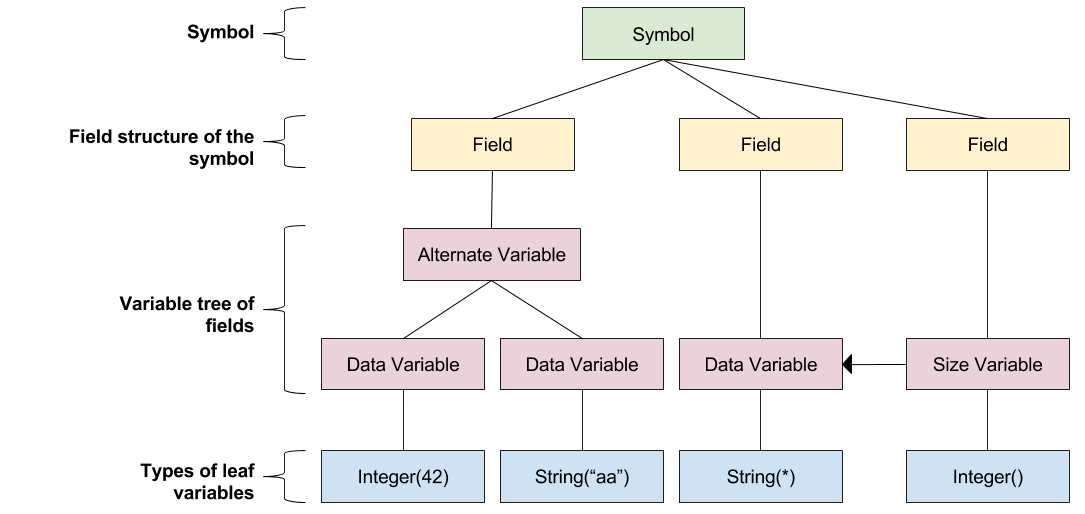
Example of Symbol definition and relationships with Field and Variable objects.#
Abstraction and Specialization of Symbols#
The use of a symbolic model is required to represent the message formats of a protocol in a compact way. However, as the objective of this platform is to analyze the robustness of a target implementation, this implies that the testing tool should be able to exchange messages with this target. We therefore need to abstract received messages into symbols that can be used by the protocol model. Conversely, we also need to specialize symbols produced by the protocol model into valid messages. To achieve this, we use an abstraction method (ABS) and a specialization (SPE) method. As illustrated in the following figure, these methods play the role of an interface between the symbolic protocol model and a communication channel on which concrete messages transit.
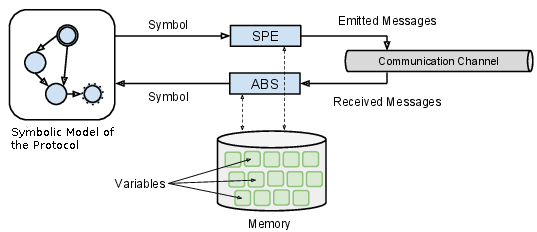
Abstraction (ABS) and Specialization (SPE) methods are interfaces between the protocol symbols and the wire messages.#
To compute or verify the constraints and relationships that
participate in the definition of the fields, the library relies on a
Memory. This memory stores the value of previously captured or emitted
fields. More precisely, the memory contains all the variables that are
needed according to the field definition during the abstraction and
specialization processes.
Modeling Data Types#
The library enables the modeling of the following data types:
Integer: The Integer type is a wrapper for the Python integer object with the capability to express more constraints regarding the sign, endianness and unit size.
HexaString: The HexaString type makes it possible to describe a sequence of bytes of arbitrary size, with a hexastring notation (e.g.
aabbcc).BLOB / Raw: The Raw type makes it possible to describe a sequence of bytes of arbitrary size, with a raw notation (e.g.
\xaa\xbb\xcc).String: The String type makes it possible to describe a field that contains sequence of String characters.
BitArray: The BitArray type makes it possible to describe a field that contains a sequence of bits of arbitrary size.
IPv4: The IPv4 type makes it possible to encode a raw Python in an IPv4 representation, and conversely to decode an IPv4 representation into a raw object.
Timestamp: The Timestamp type makes it possible to define dates in a specific format (such as Windows, Unix or MacOS X formats).
Data Types API#
Each data type provides the following API:
- class AbstractType[source]#
AbstractType is the abstract class of all the classes that represent Netzob types.
A type defines a definition domain as a unique value or specified with specific rules. For instance, an integer under a specific interval, a string with a number of chars and an IPv4 of a specific netmask.
- AbstractType.convert(typeClass)[source]#
Convert the current data type in a destination type specified in parameter.
- Parameters
typeClass (
AbstractType, required) – The Netzob type class to which the current data must be converted.- Returns
The converted current value in the specified data type.
- Return type
>>> from netzob.all import * >>> i = uint8(42) >>> r = i.convert(Raw) >>> r b'*'
- AbstractType.generate()[source]#
This method should generate data that respects the current data type.
- Returns
The data produced.
- Return type
bitarray
>>> from netzob.all import * >>> a = String(nbChars=20) >>> l = a.generate() >>> len(l) 160 >>> a = HexaString(nbBytes=20) >>> l = a.generate() >>> len(l) 160 >>> a = HexaString(b"aabbccdd") >>> a.generate() bitarray('10101010101110111100110011011101')
Some data types can have specific attributes regarding their endianness, sign and unit size. Values supported for those attributes are available through Python enumerations:
- class Endianness(value)[source]#
Enum class used to specify the endianness of a type.
- BIG = 'big'#
Endianness.BIG can be used to specify a BIG endianness of a type.
- LITTLE = 'little'#
Endianness.LITTLE can be used to specify a LITTLE endianness of a type.
- class Sign(value)[source]#
Enum class used to specify the sign of a type.
- SIGNED = 'signed'#
Sign.SIGNED can be used to specify a SIGNED sign of a type.
- UNSIGNED = 'unsigned'#
Sign.UNSIGNED can be used to specify a UNSIGNED sign of a type.
- class UnitSize(value)[source]#
Enum class used to specify the unit size of a type (i.e. the space in bits that a unitary element takes up).
- SIZE_1 = 1#
UnitSize.SIZE_1 can be used to specify a 1-bit unit size of a type.
- SIZE_16 = 16#
UnitSize.SIZE_16 can be used to specify a 16-bit unit size of a type.
- SIZE_24 = 24#
UnitSize.SIZE_24 can be used to specify a 24-bit unit size of a type.
- SIZE_32 = 32#
UnitSize.SIZE_32 can be used to specify a 32-bit unit size of a type.
- SIZE_4 = 4#
UnitSize.SIZE_4 can be used to specify a 4-bit unit size of a type.
- SIZE_64 = 64#
UnitSize.SIZE_64 can be used to specify a 64-bit unit size of a type.
- SIZE_8 = 8#
UnitSize.SIZE_8 can be used to specify a 8-bit unit size of a type.
Data Types#
Supported data types are described in detail in this chapter.
Integer Type#
In the API, the definition of an integer is done through the Integer class.
- class Integer(value=None, interval=None, unitSize=UnitSize.SIZE_16, endianness=Endianness.BIG, sign=Sign.SIGNED, default=None)[source]#
The Integer class represents an integer, with the capability to express constraints regarding the sign, the endianness and the unit size.
The Integer constructor expects some parameters:
- Parameters
value (
bitarrayorint, optional) – This parameter is used to describe a domain that contains a fixed integer. If None, the constructed Integer will represent an interval of values (seeintervalparameter).interval (a tuple with the min and the max values specified as
int, optional) – This parameter is used to describe a domain that contains an interval of permitted values. This information is used to compute the storage size of the Integer. If None, the interval will range from the minimum value to the maximum value that an integer can encode, according to its unit size, endianness and sign attributes.unitSize (
UnitSize, optional) –The unitsize, in bits, of the storage area used to encode the integer. Values must be one of UnitSize.SIZE_*.
The following unit sizes are available:
UnitSize.SIZE_8
UnitSize.SIZE_16 (default unit size)
UnitSize.SIZE_24
UnitSize.SIZE_32
UnitSize.SIZE_64
endianness (
Endianness, optional) –The endianness of the value.
The following endiannesses are available:
Endianness.BIG (default endianness)
Endianness.LITTLE
sign (
Sign, optional) –The sign of the value.
The following signs are available:
Sign.SIGNED (default sign)
Sign.UNSIGNED
default (
bitarrayorint, optional) – This parameter is the default value used in specialization.
Note
valueandintervalparameters are mutually exclusive. Setting both values raises anException.valueanddefaultparameters are mutually exclusive. Setting both values raises anException.The Integer class provides the following public variables:
- Variables
value (
bitarray) – The current value of the instance. This value is represented under the bitarray format.size (a tuple (
int,int) orint) – The size of the expected data type defined by a tuple (min integer, max integer). Instead of a tuple, an integer can be used to represent both min and max values.unitSize (
str) – The unitSize of the current value.endianness (
str) – The endianness of the current value.sign (
str) – The sign of the current value.default (
bitarray) – The default value used in specialization.
Examples of Integer object instantiations
The creation of an Integer with no parameter will create a signed, big-endian integer of 16 bits:
>>> from netzob.all import * >>> i = Integer() >>> i.generate().tobytes() b'\x94\xba'
The following example shows how to define an integer encoded in sequences of 8 bits and with a constant value of 12 (thus producing
\x0c):>>> from netzob.all import * >>> i = Integer(12, unitSize=UnitSize.SIZE_8) >>> i.generate().tobytes() b'\x0c'
The following example shows how to define an integer encoded in sequences of 32 bits and with a constant value of 12 (thus producing
\x00\x00\x00\x0c):>>> from netzob.all import * >>> i = Integer(12, unitSize=UnitSize.SIZE_32) >>> i.generate().tobytes() b'\x00\x00\x00\x0c'
The following example shows how to define an integer encoded in sequences of 32 bits in little endian with a constant value of 12 (thus producing
\x0c\x00\x00\x00):>>> from netzob.all import * >>> i = Integer(12, unitSize=UnitSize.SIZE_32, endianness=Endianness.LITTLE) >>> i.generate().tobytes() b'\x0c\x00\x00\x00'
The following example shows how to define a signed integer encoded in sequences of 16 bits with a constant value of -12 (thus producing
\xff\xf4):>>> from netzob.all import * >>> i = Integer(-12, sign=Sign.SIGNED, unitSize=UnitSize.SIZE_16) >>> i.generate().tobytes() b'\xff\xf4'
Examples of pre-defined Integer types
For convenience, common specific integer types are also available, with pre-defined values of
unitSize,signandendiannessattributes. They are used to shorten calls of singular definitions.Available big-endian pre-defined Integer types are:
int8be (or int8)
int16be (or int16)
int24be (or int24)
int32be (or int32)
int64be (or int64)
uint8be (or uint8)
uint16be (or uint16)
uint24be (or uint24)
uint32be (or uint32)
uint64be (or uint64)
Available little-endian pre-defined Integer types are:
int8le
int16le
int24le
int32le
int64le
uint8le
uint16le
uint24le
uint32le
uint64le
For example, a 16-bit little-endian unsigned Integer is classically defined like this:
>>> from netzob.all import * >>> i = Integer(42, ... unitSize=UnitSize.SIZE_16, ... sign=Sign.UNSIGNED, ... endianness=Endianness.LITTLE)
Could also be called in an equivalent form:
>>> from netzob.all import * >>> i = uint16le(42)
There is an equivalence between these two integers, for every internal value of the type:
>>> from netzob.all import * >>> i1 = Integer(42, ... unitSize=UnitSize.SIZE_16, ... sign=Sign.UNSIGNED, ... endianness=Endianness.LITTLE) >>> i2 = uint16le(42) >>> i1, i2 (42, 42) >>> i1 == i2 True
But a comparison between two specific integers of different kinds will always fail, even if their values look equivalent:
>>> from netzob.all import * >>> i1 = uint16le(42) >>> i2 = uint32le(42) >>> i1 == i2 False
And even when the concrete value seems identical, the integer objects are not:
>>> from netzob.all import * >>> i1 = uint16le(42) >>> i2 = int16le(42) >>> i1, i2 (42, 42) >>> print(i1, i2) Integer(42) Integer(42) >>> i1 == i2 False
Integer raw representations
The following examples show how to create integers with different raw representation, depending on data type attributes. In these examples, we create a 16-bit little endian, a 16-bit big endian, a 32-bit little endian and a 32-bit big endian:
>>> from netzob.all import * >>> int16le(1234).value.tobytes() b'\xd2\x04' >>> int16be(1234).value.tobytes() b'\x04\xd2' >>> int32le(1234).value.tobytes() b'\xd2\x04\x00\x00' >>> int32be(1234).value.tobytes() b'\x00\x00\x04\xd2'
Representation of Integer type objects
The following examples show the representation of Integer objects with and without a constant value.
>>> from netzob.all import * >>> i = int16le(12) >>> print(i) Integer(12)
>>> from netzob.all import * >>> i = int16le() >>> print(i) Integer(-32768,32767)
Encoding of Integer type objects
The following examples show the encoding of Integer objects with and without a constant value.
>>> from netzob.all import * >>> i = int32le(12) >>> repr(i) '12'
>>> from netzob.all import * >>> i = int32le() >>> repr(i) 'None'
Using a default value
This next example shows the usage of a default value:
>>> from netzob.all import * >>> t = uint8(default=3) >>> t.generate().tobytes() b'\x03'
>>> from netzob.all import * >>> t = Integer(interval=(1, 4), default=4) >>> t.generate().tobytes() b'\x00\x04'
BLOB / Raw Type#
In the API, the definition of a BLOB type is made through the Raw class.
- class Raw(value=None, nbBytes=None, alphabet=None, default=None)[source]#
This class defines a Raw type.
The Raw type describes a sequence of bytes of arbitrary size.
The Raw constructor expects some parameters:
- Parameters
value (
bitarrayorbytes, optional) – This parameter is used to describe a domain that contains a fixed sequence of bytes. If None, the constructed Raw will accept a random sequence of bytes, whose size may be specified (seenbBytesparameter).nbBytes (an
intor a tuple with the min and the max sizes specified asint, optional) – This parameter is used to describe a domain that contains an amount of bytes. This amount can be fixed or represented with an interval. If None, the accepted sizes will range from 0 to 8192.alphabet (a
listofbytes, optional) – The alphabet can be used to limit the bytes that can participate in the domain value. The default value is None.default (
bitarrayorbytes, optional) – This parameter is the default value used in specialization.
Note
valueandnbBytesparameters are mutually exclusive. Setting both values raises anException.valueandalphabetparameters are mutually exclusive. Setting both values raises anException.valueanddefaultparameters are mutually exclusive. Setting both values raises anException.The Raw class provides the following public variables:
- Variables
value (
bitarray) – The current value of the instance. This value is represented under the bitarray format.size (a tuple (
int,int) orint) – The internal size (in bits) of the expected data type defined by a tuple (min, max). Instead of a tuple, an integer can be used to represent both min and max values.alphabet (a
listofbytes) – The alphabet can be used to limit the bytes that can participate in the domain value.default (
bitarray) – The default value used in specialization.
The creation of a Raw type with no parameter will create a bytes object whose length ranges from 0 to 8192:
>>> from netzob.all import * >>> i = Raw() >>> len(i.generate().tobytes()) 533 >>> len(i.generate().tobytes()) 7738 >>> len(i.generate().tobytes()) 5505
The following example shows how to define a six-byte long raw object, and the use of the generation method to produce a value:
>>> from netzob.all import * >>> r = Raw(nbBytes=6) >>> len(r.generate().tobytes()) 6
It is possible to define a range regarding the valid size of the raw object:
>>> from netzob.all import * >>> r = Raw(nbBytes=(2, 20)) >>> 2 <= len(r.generate().tobytes()) <= 20 True
The following example shows the specification of a raw constant:
>>> from netzob.all import * >>> r = Raw(b'\x01\x02\x03') >>> print(r) Raw(b'\x01\x02\x03')
The alphabet optional argument can be used to limit the bytes that can participate in the domain value:
>>> from netzob.all import * >>> r = Raw(nbBytes=30, alphabet=[b"t", b"o"]) >>> data = r.generate().tobytes() >>> data b'otoottootottottooooooottttooot' >>> for c in set(data): # extract distinct characters ... print(chr(c)) t o
This next example shows the usage of a default value:
>>> from netzob.all import * >>> raw = Raw(nbBytes=2, default=b'\x01\x02') >>> raw.generate().tobytes() b'\x01\x02'
HexaString Type#
In the API, the definition of a hexastring type is made through the HexaString class.
- class HexaString(value=None, nbBytes=None, default=None)[source]#
This class defines a HexaString type.
The HexaString type describes a sequence of bytes of arbitrary size with the hexastring notation (e.g.
b'aabbcc'instead of the raw notationb'\xaa\xbb\xcc').The HexaString constructor expects some parameters:
- Parameters
value (
bitarrayorbytes, optional) – This parameter is used to describe a domain that contains a fixed hexastring. If None, the constructed hexastring will accept a random sequence of bytes, whose size may be specified (seenbBytesparameter).nbBytes (an
intor a tuple with the min and the max sizes specified asint, optional) – This parameter is used to describe a domain that contains an amount of bytes. This amount can be fixed or represented with an interval. If None, the accepted sizes will range from 0 to 8192.default (
bitarrayorbytes, optional) – This parameter is the default value used in specialization.
Note
valueandnbBytesparameters are mutually exclusive. Setting both values raises anException.valueanddefaultparameters are mutually exclusive. Setting both values raises anException.The HexaString class provides the following public variables:
- Variables
value (
bitarray) – The current value of the instance. This value is represented under the bitarray format.size (a tuple (
int,int) orint) – The size in bits of the expected data type defined by a tuple (min, max). Instead of a tuple, an integer can be used to represent both min and max values.default (
bitarray) – The default value used in specialization.
The creation of a HexaString type with no parameter will create a bytes object whose length ranges from 0 to 8192:
>>> from netzob.all import * >>> i = HexaString() >>> len(i.generate().tobytes()) 533 >>> len(i.generate().tobytes()) 7738 >>> len(i.generate().tobytes()) 5505
The following example shows how to define a hexastring object with a constant value, and the use of the generation method to produce a value:
>>> from netzob.all import * >>> h = HexaString(b"aabbcc") >>> h.generate().tobytes() b'\xaa\xbb\xcc'
The following example shows how to define a hexastring object with a variable value, and the use of the generation method to produce a value:
>>> from netzob.all import * >>> h = HexaString(nbBytes=6) >>> len(h.generate().tobytes()) 6
It is not possible to define a hexastring that contains semi-octets. However, it is possible to manually convert a BitArray into a string that represents a semi-octet. This is demonstrated in the following example where a 4-bit BitArray is converted into the ‘a’ semi-octet.
>>> import binascii >>> data = bitarray('1010', endian='big') >>> str(binascii.hexlify(data.tobytes()))[2] 'a'
This next example shows the usage of a default value:
>>> from netzob.all import * >>> t = HexaString(nbBytes=2, default=b"aabb") >>> t.generate().tobytes() b'\xaa\xbb'
String Type#
In the API, the definition of an ASCII or Unicode type is made through the String class.
- class String(value=None, nbChars=None, encoding='utf-8', eos=[], default=None)[source]#
This class defines a String type, which is used to represent String or Unicode characters.
The String type is a wrapper for the Python
strobject with the capability to express more constraints on the permitted string values.The String constructor expects some parameters:
- Parameters
value (
bitarrayorstr, optional) – This parameter is used to describe a domain that contains a fixed string. If None, the constructed string will accept a random sequence of character, whose size may be specified (seenbCharsparameter).nbChars (an
intor a tuple with the min and the max sizes specified asint, optional) – This parameter is used to describe a domain that contains an amount of characters. This amount can be fixed or represented with an interval. If None, the accepted sizes will range from 0 to 8192.encoding (
str, optional) – The encoding of the string, such as ‘ascii’ or ‘utf-8’. Default value is ‘utf-8’. Supported encodings are available on the Python reference documentation: Python Standard Encodings.eos (a
listofstr, optional) – A list defining the potential terminal characters for the string. Default value is an empty list, meaning there is no terminal character.default (
bitarrayorstr, optional) – This parameter is the default value used in specialization.
Note
valueandnbCharsparameters are mutually exclusive. Setting both values raises anException.valueanddefaultparameters are mutually exclusive. Setting both values raises anException.The String class provides the following public variables:
- Variables
value (
bitarray) – The current value of the instance. This value is represented under the bitarray format.size (a tuple (
int,int) orint) – The size in bits of the expected data type defined by a tuple (min, max). Instead of a tuple, an integer can be used to represent both min and max values.encoding (
str) – The encoding of the current value, such as ‘ascii’ or ‘utf-8’.eos (a
listofstr) – A list defining the potential terminal characters for the string.default (
bitarray) – The default value used in specialization.
Strings can be either static, dynamic with fixed sizes or even dynamic with variable sizes.
The creation of a String type with no parameter will create a string object whose length ranges from 0 to 8192:
>>> from netzob.all import * >>> i = String() >>> len(i.generate().tobytes()) 533 >>> len(i.generate().tobytes()) 2053 >>> len(i.generate().tobytes()) 6908
The following examples show how to define a static string in UTF-8:
>>> from netzob.all import * >>> s = String("Paris") >>> s.generate().tobytes() b'Paris' >>> s = String("Paris in Euro: €") >>> s.generate().tobytes() b'Paris in Euro: \xe2\x82\xac' >>> s = String("Paris in Euro: €", encoding='utf-8') >>> s.generate().tobytes() b'Paris in Euro: \xe2\x82\xac'
The following example shows the raising of an exception if input value is not valid, with the definition of a string where the associated value contains a non-String element:
>>> from netzob.all import * >>> s = String("Paris in €", encoding='ascii') Traceback (most recent call last): ... ValueError: Input value for the following string is incorrect: 'Paris in €'...
The following example shows how to define a string with a fixed size and a dynamic content:
>>> from netzob.all import * >>> s = String(nbChars=10) >>> len(s.generate().tobytes()) 10
The following example shows how to define a string with a variable size and a dynamic content:
>>> from netzob.all import * >>> s = String(nbChars=(10, 32)) >>> 10 <= len(s.generate().tobytes()) <= 32 True
String with terminal character
Strings with a terminal delimiter are supported. The following example shows the usage of a delimiter.
>>> from netzob.all import * >>> s = String(nbChars=10, eos=['\n']) >>> data = s.generate().tobytes() >>> len(data) == 10 True >>> data[-1:] == b'\n' True
Strings with a constant value and a terminal character are also supported. The following example show the usage of this case.
>>> from netzob.all import * >>> s = String("abcdef", eos=["123"]) >>> s.generate().tobytes() b'abcdef123' >>> next(Field(s).specialize()) b'abcdef123'
The
eosattribute specifies a list of values that are used as potential terminal characters. Terminal characters shall be constant (such as'\n'in the previous example).Using a default value
This next example shows the usage of a default value:
>>> from netzob.all import * >>> t = String(nbChars=(1, 4), default="A") >>> t.generate().tobytes() b'A'
BitArray Type#
In the API, the definition of a bitfield type is made through the BitArray class.
- class BitArray(value=None, nbBits=None, default=None)[source]#
This class defines a BitArray type.
The BitArray type describes an object that contains a sequence of bits of arbitrary size.
The BitArray constructor expects some parameters:
- Parameters
value (
bitarray, optional) – This parameter is used to describe a domain that contains a fixed array of bits. If None, the constructed BitArray will accept a random sequence of bits, whose size may be specified (seenbBitsparameter).nbBits (an
intor a tuple with the min and the max sizes specified asint, optional) – This parameter is used to describe a domain that contains an amount of bits. This amount can be fixed or represented with an interval. If None, the accepted sizes will range from 0 to 65535.default (
bitarray, optional) – This parameter is the default value used in specialization.
Note
valueandnbBitsparameters are mutually exclusive. Setting both values raises anException.valueanddefaultparameters are mutually exclusive. Setting both values raises anException.The BitArray class provides the following public variables:
- Variables
value (
bitarray) – The current value of the instance. This value is represented under the bitarray format.size (a tuple (
int,int) orint) – The size in bits of the expected data type defined by a tuple (min, max). Instead of a tuple, an integer can be used to represent both min and max values.constants (a
listofstr) – A list of named constants used to access the bitarray internal elements. Those elements are automatically accessible by predefined named constants, whose names can be changed. Besides, elements can be accessed in read or write mode.default (
bitarray) – The default value used in specialization.
Warning
Important note about BitArray and 8-bit aligned data
It is expected that BitArrays or successive BitArrays should produce 8-bit aligned data. For example, if two successive BitArrays are defined in a field, they should together produce 8-bit aligned data, as depicted below. In this example, an
Aggis used to concatenate two BitArrays in aField.>>> from netzob.all import * >>> domain1 = BitArray(nbBits=12) >>> domain2 = BitArray(nbBits=4) >>> f = Field(domain=Agg([domain1, domain2])) >>> data = next(f.specialize()) >>> len(data) 2
If a field/symbol model contains BitArrays that does not produce 8-bit aligned data, a
GenerationExceptionexception is raised during specialization.>>> from netzob.all import * >>> domain1 = BitArray(nbBits=12) >>> domain2 = BitArray(nbBits=5) >>> f = Field(domain=Agg([domain1, domain2])) >>> data = next(f.specialize()) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.GenerationException: specialize() produced 17 bits, which is not aligned on 8 bits. You should review the field model.
However, no exception would be raised during data abstraction in field/symbol, as the input data bytes are already 8-bit aligned.
The creation of a BitArray type with no parameter will create a bytes object whose length ranges from 0 to 65535:
>>> from netzob.all import * >>> i = BitArray() >>> len(i.generate().tobytes()) 4962 >>> len(i.generate().tobytes()) 7992 >>> len(i.generate().tobytes()) 4529
The following example shows how to define a BitArray containing a fixed constant.
>>> from netzob.all import * >>> b = BitArray('00001111') >>> b.generate().tobytes() b'\x0f'
Bitarray of fixed and dynamic sizes
The following example shows how to define a bitarray of 1 bit, 47 bits, 64 bits and then a bitarray with a variable size between 13 and 128 bits:
>>> from netzob.all import * >>> b = BitArray(nbBits=1) >>> len(b.generate()) 1
>>> from netzob.all import * >>> b = BitArray(nbBits=47) >>> len(b.generate()) 47
>>> from netzob.all import * >>> b = BitArray(nbBits=64) >>> len(b.generate()) 64
>>> from netzob.all import * >>> b = BitArray(nbBits=(13, 128)) >>> 13 <= len(b.generate()) <= 128 True
Accessing bitarray elements by named constant
In the following example, we define a bitarray with two elements. As this bitarray has a fixed length, elements are automatically accessible by predefined named constants (‘item_0’ and ‘item_1’):
>>> from netzob.all import * >>> b = BitArray('00') >>> b.constants ['item_0', 'item_1']
Bitarray element names can be changed:
>>> b.constants[0] = 'Urgent flag' >>> b.constants[1] = 'Data flag' >>> b.constants ['Urgent flag', 'Data flag']
Bitarray elements can be accessed in read or write mode:
>>> b['Urgent flag'] False >>> b['Urgent flag'] = True >>> b['Urgent flag'] True
Bitarray elements can be used with binary operators:
>>> b['Urgent flag'] |= b['Data flag'] >>> b['Urgent flag'] True
Using a default value
This next example shows the usage of a default value:
>>> from netzob.all import * >>> t = BitArray(nbBits=16, default='1111111100000000') >>> t.generate().tobytes() b'\xff\x00'
IPv4 Type#
In the API, the definition of an IPv4 type is made through the IPv4 class.
- class IPv4(value=None, network=None, endianness=Endianness.BIG, default=None)[source]#
This class defines an IPv4 type.
The IPv4 type encodes a
bytesobject in an IPv4 representation, and conversely decodes an IPv4 into a raw object.The IPv4 constructor expects some parameters:
- Parameters
value (
strornetaddr.IPAddress, optional) – This parameter is used to describe a domain that contains an IP value expressed in standard dot notation (ex: “192.168.0.10”). The default value is None.network (
strornetaddr.IPNetwork, optional) – This parameter is used to describe a domain that contains a network address expressed in standard dot notation (ex: “192.168.0.0/24”). The default value is None.endianness (
Endianness, optional) – The endianness of the current value. Values must be Endianness.BIG or Endianness.LITTLE. The default value is Endianness.BIG.default (
strornetaddr.IPAddress, optional) – This parameter is the default value used in specialization.
Note
valueandnetworkparameters are mutually exclusive. Setting both values raises anException.valueanddefaultparameters are mutually exclusive. Setting both values raises anException.The IPv4 class provides the following public variables:
- Variables
value (
bitarray) – The current value of the instance. This value is represented under the bitarray format.network (
strornetaddr.IPNetwork) – A constraint over the network. The parsed data belongs to this network or not.endianness (
Endianness) – The endianness of the value. Values must be Endianness.BIG or Endianness.LITTLE.default (
bitarray) – The default value used in specialization.
The creation of an IPv4 type with no parameter will create a random bytes object of 4 bytes:
>>> from netzob.all import * >>> i = IPv4() >>> i.generate().tobytes() b'\x93\tn|'
The following examples show the use of an IPv4 type:
>>> from netzob.all import * >>> ip = IPv4("192.168.0.10") >>> ip.value bitarray('11000000101010000000000000001010')
It is also possible to specify an IPv4 type that accepts a range of IP addresses, through the
networkparameter, as shown in the following example:>>> from netzob.all import * >>> ip = IPv4(network="10.10.10.0/27") >>> IPv4(ip.generate()) # initialize with the generated bitarray value 10.10.10.0
This next example shows the usage of a default value:
>>> from netzob.all import * >>> t = IPv4(default='127.0.0.1') >>> t.generate().tobytes() b'\x7f\x00\x00\x01'
Timestamp Type#
In the API, the definition of a timestamp type is done through the Timestamp class.
- class Timestamp(value=None, epoch=Epoch.UNIX, unity=Unity.SECOND, unitSize=UnitSize.SIZE_32, endianness=Endianness.BIG, sign=Sign.UNSIGNED, default=None)[source]#
This class defines a Timestamp type.
The Timestamp type defines dates in a specific format (such as Windows, Unix or MacOSX formats).
The Timestamp constructor expects some parameters:
- Parameters
value (
bitarrayorint, optional) – This parameter is used to describe a domain that contains a fixed timestamp (in seconds by default). IfNone, the default generated value is the current time in UTC.epoch (
Epoch, optional) –This parameter is the initial date expressed in UTC from which timestamp is measured.
Available values for epoch parameter are:
Epoch.WINDOWS = datetime(1601, 1, 1)
Epoch.MUMPS = datetime(1840, 12, 31)
Epoch.VMS = datetime(1858, 11, 17)
Epoch.EXCEL = datetime(1899, 12, 31)
Epoch.NTP = datetime(1900, 1, 1)
Epoch.MACOS_9 = datetime(1904, 1, 1)
Epoch.PICKOS = datetime(1967, 12, 31)
Epoch.UNIX = datetime(1970, 1, 1) (default epoch)
Epoch.FAT = datetime(1980, 1, 1)
Epoch.GPS = datetime(1980, 1, 6)
Epoch.ZIGBEE = datetime(2000, 1, 1)
Epoch.COCOA = datetime(2001, 1, 1)
unity (
Unity, optional) –This specifies the unity of the value (seconds, milliseconds, nanoseconds).
Available values for unity parameter are:
Unity.SECOND = 1 (default unity)
Unity.DECISECOND = 10
Unity.CENTISECOND = 100
Unity.MILLISECOND = 1000
Unity.MICROSECOND = 1000000
Unity.NANOSECOND = 10000000000
unitSize (
UnitSize, optional) –The unitsize of the current value. Values must be one of
UnitSize.SIZE_*.The following unit sizes are available:
UnitSize.SIZE_32 (default unit size)
UnitSize.SIZE_64
endianness (
Endianness, optional) – The endianness of the current value. Values must beEndianness.BIGorEndianness.LITTLE. The default value isEndianness.BIG.sign (
Sign, optional) – The sign of the current value. Values must beSign.SIGNEDorSign.UNSIGNED. The default value isSign.UNSIGNED.default (
bitarrayorint, optional) – This parameter is the default value used in specialization.
Note
valueanddefaultparameters are mutually exclusive. Setting both values raises anException.The Timestamp class provides the following public variables:
- Variables
value (
bitarray) – The current value of the instance. This value is represented under the bitarray format.size (a tuple (
int,int) orint) – The size in bits of the expected data type defined by a tuple (min, max). Instead of a tuple, an integer can be used to represent both min and max values.epoch (
Epoch) – The initial date expressed in UTC from which timestamp is measured.unity (
Unity) – This specifies the unity of the timestamp (seconds, milliseconds, nanoseconds).unitSize (
UnitSize, optional) – The unitsize of the current value.sign (
Sign) – The sign of the current value.endianness (
Endianness) – The endianness of the current value.default (
bitarray) – The default value used in specialization.
The creation of a Timestamp type with no parameter will create a bytes object of 4 bytes containing the current time in seconds from
Epoch.UNIX:>>> from netzob.all import * >>> i = Timestamp() >>> len(i.generate().tobytes()) 4
In the following example, a Timestamp data is created from a datetime and represented as 32 bits:
>>> import time >>> import datetime >>> from netzob.all import * >>> date = datetime.datetime(2015, 10, 10, 17, 54, 2) >>> time_timestamp = time.mktime(date.timetuple()) >>> timestamp = Timestamp(time_timestamp) >>> timestamp.size (0, 4294967296) >>> timestamp.value bitarray('01010110000110010101000010111010') >>> timestamp.sign Sign.UNSIGNED >>> timestamp.endianness Endianness.BIG >>> timestamp Sat Oct 10 17:54:02 2015
This next example shows the usage of a default value:
>>> from netzob.all import * >>> t = Timestamp(default=1234) >>> t.generate().tobytes() b'\x00\x00\x04\xd2'
>>> from netzob.all import * >>> f0 = Field(Raw(b"00"), name="Start") >>> f1 = Field(Timestamp(1444737333), name="Timestamp") >>> f2 = Field(Raw(b"00"), name="End") >>> s = Symbol(fields=[f0, f1, f2]) >>> s.messages = [RawMessage(next(s.specialize())) for x in range(5)] >>> print(s.str_data()) Start | Timestamp | End ----- | ------------- | ---- '00' | b'V\x1c\xf15' | '00' '00' | b'V\x1c\xf15' | '00' '00' | b'V\x1c\xf15' | '00' '00' | b'V\x1c\xf15' | '00' '00' | b'V\x1c\xf15' | '00' ----- | ------------- | ----
>>> s.fields[1].addEncodingFunction(TypeEncodingFunction(Timestamp)) >>> print(s.str_data()) Start | Timestamp | End ----- | -------------------------- | ---- '00' | 'Tue Oct 13 11:55:33 2015' | '00' '00' | 'Tue Oct 13 11:55:33 2015' | '00' '00' | 'Tue Oct 13 11:55:33 2015' | '00' '00' | 'Tue Oct 13 11:55:33 2015' | '00' '00' | 'Tue Oct 13 11:55:33 2015' | '00' ----- | -------------------------- | ----
Modeling Fields#
In the API, field modeling is done through the Field class.
- class Field(domain=None, name='Field', isPseudoField=False)[source]#
The Field class is used in the definition of a Symbol structure.
A Field describes a chunk of a Symbol and is specified by a definition domain, representing the set of values the field accepts.
The Field constructor expects some parameters:
- Parameters
domain (
Variable,AbstractType,bytes,str,int,bitarray, orlistofField, optional) – The definition domain of the field (i.e. the set of values the field accepts). If not specified, the default definition domain will beRaw(), meaning it accepts any values. When this parameter is a list of fields, the constructor setself.fields=domainandself.domain=None. Otherwise, it sets thedomainattribute. During this later operation, a normalization is done in order to convert the provided domain into aVariable.name (
str, optional) – The name of the field. If not specified, the default name will be “Field”.isPseudoField (
bool, optional) – A flag indicating if the field is a pseudo field, meaning it is used internally to help the computation of the value of another field, but does not directly produce data. The default value is False.
The Field class provides the following public variables:
- Variables
domain (
Variable) – The definition domain of the field (i.e. the set of values the field accepts). Only applicable when the current field has a definition domain. Setting this attribute will clean the list of sub-fields (i.e. thefieldsattribute will be set to[]).Nonewhenself.fieldsis set.name (
str) – The name of the field.description (
str) – The description of the field.fields (list[Field]) – The sorted list of sub-fields. Only applicable when the current field has sub-fields. Setting this attribute will clean the definition domain of the current field.
isPseudoField (
bool) – A flag indicating if the field is a pseudo field, meaning it is used internally to help the computation of the value of another field, but does not directly produce data.
Fields hierarchy
A field can be composed of sub-fields. This is useful for example to separate a header, composed of multiple fields, from its payload. The parent field can be seen as a facility to access a group of fields.
In the following example, the
fheaderfield is a parent field for a group of sub-fields. The parent field does not contain any concrete data, contrary to its sub-fields.>>> from netzob.all import * >>> fh0 = Field(name='fh0') >>> fh1 = Field(name='fh1') >>> fheader = Field([fh0, fh1], name='fheader')
More generally, a field is part of a tree whose root is a symbol and whose all other nodes are fields. Hence, a field always has a parent which can be another field or a symbol if it is the root.
Field definition domain
The value that can take a field is defined by its definition domain. The definition domain of a field can take multiple forms, in order to easily express basic types (such as Integer or String) or to model complex data structures (such as alternatives, repetitions or sequences).
The following examples present the different forms that make it possible to express the same field content (i.e. an Integer with a constant value of 10):
>>> from netzob.all import * >>> f = Field(Data(Integer(10))) >>> f = Field(Integer(10)) >>> f = Field(10)
If these fields are equivalent, this is because the first parameter of the Field constructor is
domain, thus its name can be omitted. Besides, the domain parameter will be parsed by a factory, which accepts either the canonical form of a definition domain (such as domain=Data(Integer(10))) or a shortened form (such as domain=Integer(10), or even domain=10). In the later case, this means that it is possible to use a Python native type that will be automatically converted to its equivalent in Netzob type. Supported Python native types arebytes(converted inRaw),str(converted inString),int(converted inInteger) andbitarray(converted inBitArray).A domain may be composed of basic types, or complex data structures. The following examples show how to express data structures composed of 1) an alternative between the integers 10 and 20, 2) a repetition of the string a, and 3) an aggregate (or concatenation) of the strings aa and bb:
>>> from netzob.all import * >>> f = Field(Alt([10, 20])) >>> f = Field(Repeat("a", nbRepeat=(4,8))) >>> f = Field(Agg(["aa", "bb"]))
Relationships between fields
A field can have its value related to the content of another field. Such relationships may be specified through specific domain objects, such as
SizeorValueclasses.The following example describes a size relationship with a String field:
>>> from netzob.all import * >>> f0 = Field(String("test")) >>> f1 = Field(Size(f0)) >>> fheader = Field([f0, f1])
Pseudo fields
Sometimes, a specific field can be needed to express a complex data structure that depends on external data. This is the purpose of the isPseudoField flag. This flag indicates that the current field is only used for the computation of the value of another field, but does not produce real content during specialization. The following example shows a pseudo field that contains external data, and a real field whose content is the size of the external data:
>>> from netzob.all import * >>> f_pseudo = Field(domain="An external data", isPseudoField=True) >>> f_real = Field(domain=Size(f_pseudo)) >>> fheader = Field([f_pseudo, f_real])
A real example of a pseudo field is found in the UDP checksum, which relies on a pseudo IP header for its computation.
Encoding functions applied to fields
Encoding functions represent functions which apply to modify the encoding of a data. The following example shows the use of the
Base64EncodingFunctionfunction to automatically decode base64 strings in the f1 field:>>> from netzob.all import * >>> m1 = "hello YWxs" >>> m2 = "hello bXkgbG9yZA==" >>> m3 = "hello d29ybGQ=" >>> messages = [RawMessage(m1), RawMessage(m2), RawMessage(m3)] >>> f0 = Field(name="f0", domain=String("hello ")) >>> f1 = Field(name="f1", domain=String(nbChars=(0, 20))) >>> s = Symbol(fields=[f0, f1], messages=messages) >>> print(s.str_data()) f0 | f1 -------- | -------------- 'hello ' | 'YWxs' 'hello ' | 'bXkgbG9yZA==' 'hello ' | 'd29ybGQ=' -------- | -------------- >>> f1.addEncodingFunction(Base64EncodingFunction(encode_data = False)) >>> print(s.str_data()) f0 | f1 -------- | --------- 'hello ' | 'all' 'hello ' | 'my lord' 'hello ' | 'world' -------- | ---------
Field examples
Here are examples of fields:
a field containing the integer value 100
>>> f = Field(100)
a field containing a specific binary: ‘1000’ = 8 in decimal
>>> f = Field(0b1000)
a field containing a raw value of 8 bits (1 byte)
>>> f = Field(Raw(nbBytes=8))
a field with a specific raw value
>>> f = Field(Raw(b'\x00\x01\x02\x03'))
a field representing a random IPv4:
>>> f = Field(IPv4())
a field representing a random String of 6 characters length:
>>> f = Field(String(nbChars=6))
a field representing a random String with length between 5 and 20 characters:
>>> payloadField = Field(String(nbChars=(5, 20)))
a field whose value is the size of the payloadField:
>>> f = Field([Size(payloadField)])
a field representing an alternative between two different strings, either “john” or “kurt”:
>>> f = Field(["john", "kurt"])
a field representing a decimal (10) or a String of 16 chars:
>>> f = Field([10, String(nbChars=(16))])
- copy()[source]#
Copy the current object as well as all its dependencies.
- Returns
A new object of the same type.
- Return type
- str_structure(preset=None)[source]#
Returns a string which denotes the current field definition using a tree display.
- Returns
The current field represented as a string.
- Return type
str- Parameters
preset (
Preset, optional) – The configuration used to parameterize values in fields and variables.
>>> from netzob.all import * >>> f1 = Field(String(), name="field1") >>> f2 = Field(Integer(interval=(10, 100)), name="field2") >>> f3 = Field(Raw(nbBytes=14), name="field3") >>> field = Field([f1, f2, f3], name="Main field") >>> print(field.str_structure()) Main field |-- field1 |-- Data (String(nbChars=(0,8192))) |-- field2 |-- Data (Integer(10,100)) |-- field3 |-- Data (Raw(nbBytes=14))
- abstract(data, preset=None, memory=None)#
The
abstract()method is used to abstract the given data bytes with the current symbol (or field) model. This method also works on fields, in order to abstract abytesinto a field object.Similarly to the
specialize()method, it is possible to indicate a Preset configuration that will be used to check content parsed for specific fields. However, for theabstract()method, it is only possible to specify field names for keys of the Preset configuration. The reason of this restriction is that theabstract()method returns anOrderedDictcontaining also field names as keys.The
abstract()method expects some parameters:- Parameters
data (
bytes, required) – The concrete message to abstract in symbol (or field).preset (
Preset, optional) – The configuration used to check values in symbol (or field) structure obtained after message parsing.memory (
Memory, optional) – A memory used to store variable values during specialization and abstraction of sequence of symbols (or fields). The default value is None.
- Returns
The structure of the parsed data.
- Return type
An
OrderedDictwhere keys arestrand values arebytes- Raises
AbstractionExceptionif an error occurs while abstracting the data
Note
When using the
abstract()method, it is important to explicitly name all the fields with different names, because the resulting OrderedDict will use field names as its keys.Abstracting data into a field
The following code shows an example of abstracting a data according to a field definition:
>>> from netzob.all import * >>> messages = ["john, what's up in {} ?".format(city) ... for city in ['Paris', 'Berlin']] >>> >>> f1a = Field(name="name", domain="john") >>> f2a = Field(name="question", domain=", what's up in ") >>> f3a = Field(name="city", domain=Alt(["Paris", "Berlin"])) >>> f4a = Field(name="mark", domain=" ?") >>> f = Field([f1a, f2a, f3a, f4a], name="field-john") >>> >>> for m in messages: ... structured_data = f.abstract(m) ... print(structured_data) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Paris'), ('mark', b' ?')]) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Berlin'), ('mark', b' ?')])
Abstracting data into a symbol
The following code shows an example of abstracting a data according to a symbol definition:
>>> from netzob.all import * >>> messages = ["john, what's up in {} ?".format(city) ... for city in ['Paris', 'Berlin']] >>> >>> f1a = Field(name="name", domain="john") >>> f2a = Field(name="question", domain=", what's up in ") >>> f3a = Field(name="city", domain=Alt(["Paris", "Berlin"])) >>> f4a = Field(name="mark", domain=" ?") >>> s = Symbol([f1a, f2a, f3a, f4a], name="Symbol-john") >>> >>> for m in messages: ... structured_data = s.abstract(m) ... print(structured_data) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Paris'), ('mark', b' ?')]) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Berlin'), ('mark', b' ?')])
Usage of Symbol for traffic generation and parsing
A Symbol class may be used to generate concrete messages according to its field definition, through the
specialize()method, and may also be used to abstract a concrete message into its associated symbol through theabstract()method:>>> from netzob.all import * >>> f0 = Field("aaaa", name="f0") >>> f1 = Field(" # ", name="f1") >>> f2 = Field("bbbbbb", name="f2") >>> s = Symbol(fields=[f0, f1, f2]) >>> concrete_message = next(s.specialize()) >>> concrete_message b'aaaa # bbbbbb' >>> s.abstract(concrete_message) OrderedDict([('f0', b'aaaa'), ('f1', b' # '), ('f2', b'bbbbbb')])
Usage of Preset during message abstraction
The following code shows an example of abstracting a data according to a symbol definition and a defined Preset configuration:
>>> from netzob.all import * >>> >>> f1 = Field(name="name", domain="john") >>> f2 = Field(name="question", domain=", what's up in ") >>> f3 = Field(name="city", domain=Alt(["Paris", "Berlin"])) >>> f4 = Field(name="mark", domain=" ?") >>> symbol = Symbol([f1, f2, f3, f4], name="Symbol-john") >>> >>> # We build a Preset configuration indicating that we expect "Paris" for the field f3 >>> preset = Preset(symbol) >>> preset[f3] = b"Paris" >>> >>> data = "john, what's up in Berlin ?" >>> data_structure = symbol.abstract(data, preset=preset) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.AbstractionException: With the symbol/field 'Symbol-john', can abstract the data: 'john, what's up in Berlin ?', but some parsed values do not match the expected preset. >>> >>> data = "john, what's up in Paris ?" >>> data_structure = symbol.abstract(data, preset=preset) >>> >>> data_structure OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Paris'), ('mark', b' ?')])
- count(preset=None)[source]#
The
count()method computes the expected number of unique messages produced, considering the initial field model and the preset configuration.The
count()method expects the following parameters:- Parameters
preset (
Preset, optional) – The configuration used to parameterize values in fields and variables. This configuration will impact the expected number of unique messages the field would produce.- Returns
The number of unique values the field specialization can produce.
- Return type
int
Note
The theoretical value returned by
count()may be huge. Therefore, we force the returned value to beMAXIMUM_POSSIBLE_VALUES(86400000000), if the theoretical result is beyond this threshold. This limit corresponds to 1 day of data generation based on a generation bandwith of 1 million per second.>>> # Field definition >>> from netzob.all import * >>> from netzob.Fuzzing.Generators.DeterministGenerator import DeterministGenerator >>> f1 = Field(uint16(interval=(50, 1000))) >>> f2 = Field(uint8()) >>> f3 = Field(uint8()) >>> f = Field([f1, f2, f3]) >>> >>> # Count the expected number of unique produced messages >>> f.count() # Here, the following computation is done: 951*256*256 (f1 is able to produce 1000-50+1=951 possible values, based on its interval) 62324736 >>> >>> # Specify a preset configuration for field 'f2' >>> preset = Preset(f) >>> preset[f2] = 42 >>> f.count(preset) # Here, the following computation is done: 951*1*256 (as the f2 field value is set to 42, f2 can now produce only 1 possible value) 243456 >>> >>> # Specify a preset configuration for field 'f3' by activating fuzzing >>> preset.fuzz(f3, generator='determinist') >>> >>> f.count(preset) # Here, the following computation is done: 951*1*29 (29 corresponds to the number of possible values generated by the determinist generator) 27579
- getField(field_name)#
Retrieve a sub-field based on its name.
- Parameters
field_name (
str, required) – the name of theFieldobject- Returns
The sub-field object.
- Return type
Field- Raises
KeyError – when the field has not been found
The following example shows how to retrieve a sub-field based on its name:
>>> from netzob.all import * >>> f1 = Field("hello", name="f1") >>> f2 = Field("hello", name="f2") >>> f3 = Field("hello", name="f3") >>> fheader = Field(name="fheader") # create a Field named 'fheader' >>> fheader.fields = [f1, f2, f3] # this Field is parent of 3 existing Fields >>> type(fheader.getField('f2')) # get the sub-field named 'f2' <class 'netzob.Model.Vocabulary.Field.Field'> >>> >>> s = Symbol([f1, f2, f3]) >>> type(s.getField('f2')) # get the field named 'f2' in the symbol <class 'netzob.Model.Vocabulary.Field.Field'>
- getSymbol()#
Return the symbol to which this field is attached.
- Returns
The associated symbol if available.
- Return type
- Raises
NoSymbolException
To retrieve the associated symbol, this method recursively calls the parent of the current object until the root is found.
If the root is not a
Symbol, this raises an Exception.The following example shows how to retrieve the parent symbol from a field object:
>>> from netzob.all import * >>> field = Field("hello", name="F0") >>> symbol = Symbol([field], name="S0") >>> field.getSymbol() S0 >>> type(field.getSymbol()) <class 'netzob.Model.Vocabulary.Symbol.Symbol'>
- specialize(preset=None, memory=None) Iterator[bytes][source]#
The
specialize()method is intended to produce concretebytesdata based on the field model. This method returns a Python generator that in turn provides databytesobject at each call tonext(generator).- Parameters
preset (
Preset, optional) – The configuration used to parameterize values in fields and variables.memory (
Memory, optional) – A memory used to store variable values during specialization and abstraction of successive fields, especially to handle inter-symbol relationships. If None, a temporary memory is created by default and used internally during the scope of the specialization process.
- Returns
A generator that provides data
bytesat each call tonext(generator).- Return type
Generator[bytes]- Raises
GenerationExceptionif an error occurs while specializing the field.
The following example shows the
specialize()method used for a field which contains a string with a constant value.>>> from netzob.all import * >>> f = Field(String("hello")) >>> next(f.specialize()) b'hello'
The following example shows the
specialize()method used for a field which contains a string with a variable value.>>> from netzob.all import * >>> f = Field(String(nbChars=4)) >>> len(next(f.specialize())) 4
Modeling Variables#
The definition domain of a field is represented by a tree of variables, containing leaf and node variables. Each variable follows a common API, which is described in the abstract class AbstractVariable:
- class AbstractVariable[source]#
A variable participates in the definition domain of a field.
The AbstractVariable class defines the API of a variable, which can be a leaf or a node variable.
Modeling Data Variables#
In the API, data variable modeling is made through the class Data.
- class Data(dataType, name=None, scope=None)[source]#
The Data class is a variable which embeds specific content.
A Data object stores the definition domain of a variable and the constraints over it, through a
Typeobject.The Data constructor expects some parameters:
- Parameters
dataType (
AbstractType, required) – The type of the data (for example Integer, Raw, String, …).name (
str, optional) – The name of the data (if None, the name will be generated).scope (
Scope, optional) – The Scope strategy defining how the Data value is used during the abstraction and specialization process. The default strategy isScope.NONE.
The Data class provides the following public variables:
- Variables
dataType (
AbstractType) – The type of the data.name (
str) – The name of the variable (Read-only).
The following example shows the definition of the Data pseudo with a String type and a “hello” default value. This means that this Data object accepts any string, and the default generated value of this object is “hello”.
>>> from netzob.all import * >>> s = String(nbChars=5, default='hello') >>> data = Data(dataType=s, name="pseudo") >>> print(data.dataType) String(nbChars=5) >>> data.name 'pseudo' >>> s.generate().tobytes() b'hello'
Modeling Node Variables#
Multiple variables can be combined to form a complex and precise specification of the values that are accepted by a field. Four complex variable types are provided:
Aggregate node variables, which can be used to model a concatenation of variables.
Alternate node variables, which can be used to model an alternative of multiple variables.
Repeat node variables, which can be used to model a repetition of a variable.
Optional node variables, which can be used to model a variable that may or may not be present.
Those node variables are described in detail in this chapter.
Aggregate Domain#
In the API, the definition of a concatenation of variables is made through the Agg class.
- class Agg(children=None, last_optional=False, name=None)[source]#
The Agg class is a node variable that represents a concatenation of variables.
An aggregate node concatenates the values that are accepted by its children nodes. It can be used to specify a succession of tokens.
The Agg constructor expects some parameters:
- Parameters
children (a
listofVariable, optional) – The sequence of variable elements contained in the aggregate. The default value is None.last_optional (
bool, optional) – A flag indicating if the last element of the children is optional or not. The default value is False.name (
str, optional) – The name of the variable (if None, the name will be generated).
The Agg class supports modeling of direct recursions on the right. To do so, the flag
SELFis available, and should only be used in the last position of the aggregate (see example below).The Agg class provides the following public variables:
- Variables
children (a list of
Variable) – The sorted typed list of children attached to the variable node.
Aggregate examples
For example, the following code represents a field that accepts values that are made of a String of 3 to 20 random characters followed by a “.txt” extension:
>>> from netzob.all import * >>> t1 = String(nbChars=(3,20)) >>> t2 = String(".txt") >>> f = Field(Agg([t1, t2]))
The following example shows an aggregate between BitArray variables:
>>> from netzob.all import * >>> f = Field(Agg([BitArray('01101001'), BitArray(nbBits=3), BitArray(nbBits=5)])) >>> t = next(f.specialize()) >>> len(t) 2
Examples of Agg internal attribute access
>>> from netzob.all import * >>> domain = Agg([Raw(), String()]) >>> print(domain.children[0].dataType) Raw(nbBytes=(0,8192)) >>> print(domain.children[1].dataType) String(nbChars=(0,8192)) >>> domain.children.append(Agg([10, 20, 30])) >>> len(domain.children) 3 >>> domain.children.remove(domain.children[0]) >>> len(domain.children) 2
Abstraction of aggregate variables
This example shows the abstraction process of an Aggregate variable:
>>> from netzob.all import * >>> v1 = String(nbChars=(1, 10)) >>> v2 = String(".txt") >>> f0 = Field(Agg([v1, v2]), name="f0") >>> f1 = Field(String("!"), name="f1") >>> f = Field([f0, f1]) >>> data = "john.txt!" >>> f.abstract(data) OrderedDict([('f0', b'john.txt'), ('f1', b'!')])
In the following example, an Aggregate variable is defined. A message that does not correspond to the expected model is then parsed, thus an exception is returned:
>>> from netzob.all import * >>> v1 = String(nbChars=(1, 10)) >>> v2 = String(".txt") >>> f0 = Field(Agg([v1, v2]), name="f0") >>> f1 = Field(String("!"), name="f1") >>> f = Field([f0, f1]) >>> data = "johntxt!" >>> f.abstract(data) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.AbstractionException: With the symbol/field 'Field', cannot abstract the data: 'johntxt!'. Error: 'No parsing path returned while parsing 'b'johntxt!'''
Specialization of aggregate variables
This example shows the specialization process of an Aggregate variable:
>>> from netzob.all import * >>> d1 = String("hello") >>> d2 = String(" john") >>> f = Field(Agg([d1, d2])) >>> next(f.specialize()) b'hello john'
Optional last variable
This example shows the specialization and parsing of an aggregate with an optional last variable:
>>> from netzob.all import * >>> a = Agg([int8(2), int8(3)], last_optional=True) >>> f = Field(a) >>> res = next(f.specialize()) >>> res == b'\x02' or res == b'\x02\x03' True >>> d = b'\x02\x03' >>> f.abstract(d) OrderedDict([('Field', b'\x02\x03')]) >>> d = b'\x02' >>> f.abstract(d) OrderedDict([('Field', b'\x02')])
Modeling indirect imbrication
The following example shows how to specify a field with a structure (
v2) that can contain another structure (v0), through a tierce structure (v1). The flaglast_optionalis used to indicate that the specialization or parsing of the last element of the aggregatesv1andv2is optional.>>> from netzob.all import * >>> v0 = Agg(["?", int8(4)]) >>> v1 = Agg(["!", int8(3), v0], last_optional=True) >>> v2 = Agg([int8(2), v1], last_optional=True) >>> f = Field(v2) >>> >>> # Test specialization >>> res = next(f.specialize()) >>> res == b'\x02' or res == b'\x02!\x03' or res == b'\x02!\x03?\x04' True >>> >>> # Test parsing >>> f.abstract(res) OrderedDict([('Field', b'\x02')])
Warning
Important note about recursion
The library can handle both direct and indirect recursion. However, there is a limitation requiring the use of a recursing variable on the right side of a statement. Any other behavior could lead to infinite recursion during the loading of the model. To help understand what syntax should be preferred, here is a list of annotated BNF syntaxes.
invalid syntaxes:
A ::= [A] integer <recursion on the left side> B ::= ( "(" B ) | ( "." ")" ) <recursion on the middle>valid adaptations from above examples:
A ::= integer+ <recursion is replaced by a repeat approach> B ::= B' ")" <split the statement ...> B' ::= ( "(" B ) | "." <direct recursion converted in an indirect one on the right>valid recursion examples:
C ::= "." C* <a string with one or more dot characters> D ::= ( D | "." )* <a string with zero or more dot characters>Modeling direct recursion, simple example
The following example shows how to specify a field with a structure (
v) that can optionally contain itself. To model such recursive structure, theSELFflag has to be used in the last position of the aggregate.>>> from netzob.all import * >>> v = Agg([int8(interval=(1, 5)), SELF], last_optional=True) >>> f = Field(v) >>> >>> # Test specialization >>> res = next(f.specialize()) >>> res b'\x02\x04\x01' >>> >>> # Test parsing >>> res_data = f.abstract(res) True
Modeling direct recursion, more complex example
This example introduces a recursion in the middle of an expression by modeling a pair group of parentheses (
'('and')'), around a single character ('+'). The BNF syntax of this model would be:parentheses ::= ( "(" parentheses ) | ( "+" ")" )This syntax introduces a recursivity in the middle of the left statement, which is not supported. Instead, this syntax could be adapted to move the recursivity to the right.
parentheses ::= left right left ::= ( "(" parentheses ) | "+" right ::= ")"The following models describe this issue and provide a workaround.
BAD way
>>> from netzob.all import * >>> parentheses = Agg(["(", Alt([SELF, "+"]), ")"]) Traceback (most recent call last): ValueError: SELF can only be set at the last position of an Agg
GOOD way
>>> from netzob.all import * >>> parentheses = Agg([]) >>> left = Agg(["(", Alt([parentheses, "+"])]) >>> right = ")" >>> parentheses.children += [left, right] >>> >>> symbol = Symbol([Field(parentheses)]) >>> next(symbol.specialize()) b'((+))'
Modeling indirect recursion, simple example
The following example shows how to specify a field with a structure (
v2) that contains another structure (v1), which can itself contain the first structure (v2). The flaglast_optionalis used to indicate that the specialization or parsing of the last element of the aggregatev2is optional.>>> from netzob.all import * >>> v1 = Agg([]) >>> v2 = Agg([int8(interval=(1, 3)), v1], last_optional=True) >>> v1.children = ["!", v2] >>> f = Field(v2) >>> res = next(f.specialize()) >>> res b'\x03!\x03!\x03!\x03' >>> >>> # Test parsing >>> f.abstract(res) OrderedDict([('Field', b'\x01!\x01')])
Modeling indirect recursion, more complex example
The following syntax provides a way to parse and specialize a subset of mathematical expressions including pair group of parentheses, digits from 0 to 9 and two arithmetic operators (‘+’ and ‘*’).
num ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" operator ::= "+" | "*" operation ::= left [right] left ::= num | subop right ::= operator operation subop ::= "(" operation ")"The following examples should be compatible with these expressions:
1 + 2 1 + 2 + 3 1 + (2 + 3) (1 + 2) + 3 (1 + 2) + 3 + 4 1 + (2 * 3) + (4 * 5) 1 + (2 * (3 + 4)) + 5 1 + ((2 * 3) * 4) * 5
These last expressions should not be compatible with these expressions:
1 1 ** 2 1 * (2 * 3 1 *
This example of indirect recursion introduces a recursion of the operation statement, called in the subop statement.
>>> from netzob.all import * >>> num = Alt(["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]) >>> operator = Alt([" + ", " * "]) >>> operation = Agg([], last_optional=True) >>> subop = Agg(["(", operation, ")"]) >>> left = Alt([num, subop]) >>> right = Agg([operator, operation]) >>> operation.children += [left, right] >>> sym = Symbol([Field(operation)]) >>> next(sym.specialize()) b'((((4 * 8 * 4) + 5 + 9 + 0) * 7 * 0 + (4 + 9 + (3 * 4 + 2) * 0) * 9) + 4 * 7)'
Alternate Domain#
In the API, the definition of an alternate of variables is made through the Alt class.
- class Alt(children=None, callback=None, name=None)[source]#
The Alt class is a node variable that represents an alternative of variables.
A definition domain can take the form of a combination of permitted values/types/domains. This combination is represented by an alternate node. It can be seen as an OR operator between two or more children nodes.
The Alt constructor expects some parameters:
- Parameters
children (a
listofVariable, optional) – The set of variable elements permitted in the alternative. The default is None.callback (
Callable, optional) – The callback function that may be used to determine the child index to select. The default is None.name (
str, optional) – The name of the variable (if None, the name will be generated).
The Alt class provides the following public variables:
- Variables
children (a list of
Variable) – The sorted typed list of children attached to the variable node.callback (
Callable) – The callback function that may be used to determine the child index to select.
Callback prototype
The callback function that can be used to determine the child index to select has the following prototype:
- cbk_child_selection(path, children)
The
childrenis a list ofVariable. Eachchildcan have children if it is a node. Access to child values, as well as to its own children values, is done through thepathdata structure, thanks to its methodshasData()andgetData(). Those methods therefore allow access to a hierarchy of elements for which thechildis the root element:path.hasData(element)will return abooltelling if a data has been specialized or parsed for the elementVariable.path.getData(element)will return abitarraythat corresponds to the value specialized or parsed for the elementVariable.
It is possible to test if a
childvariable is a node of the tree structure through theisnode(child)method. A node may represent anAgg, anAlt, aRepeator anOptvariable. Access to the node leafs is possible with the attributechildren(i.e.child.children). The type of the children leafs is alsoVariable.Alt examples
The following code denotes an alternate object that accepts either the string “filename1.txt” or the string “filename2.txt”:
>>> from netzob.all import * >>> t1 = String("filename1.txt") >>> t2 = String("filename2.txt") >>> domain = Alt([t1, t2])
Examples of Alt internal attribute access
>>> from netzob.all import * >>> domain = Alt([Raw(), String()]) >>> print(domain.children[0].dataType) Raw(nbBytes=(0,8192)) >>> print(domain.children[1].dataType) String(nbChars=(0,8192))
Example of a deterministic Alt computation
>>> def cbk(path, children): ... return -1 >>> f = Field(Alt([String(_) for _ in "abc"], callback=cbk), "alt") >>> sym = Symbol([f]) >>> data = next(sym.specialize()) >>> print(data) b'c' >>> sym.abstract(data) OrderedDict([('alt', b'c')])
Abstraction of alternate variables
This example shows the abstraction process of an Alternate variable:
>>> from netzob.all import * >>> v0 = String("john") >>> v1 = String("kurt") >>> f0 = Field(Alt([v0, v1]), name='f0') >>> s = Symbol([f0]) >>> data = "john" >>> s.abstract(data) OrderedDict([('f0', b'john')]) >>> data = "kurt" >>> s.abstract(data) OrderedDict([('f0', b'kurt')])
In the following example, an Alternate variable is defined. A message that does not correspond to the expected model is then parsed, thus an exception is returned:
>>> data = "nothing" >>> s.abstract(data) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.AbstractionException: With the symbol/field 'Symbol', cannot abstract the data: 'nothing'. Error: 'No parsing path returned while parsing 'b'nothing'''
Repeat Domain#
In the API, the definition of a repetition of variables, or sequence, is made through the Repeat class.
- class Repeat(child, nbRepeat, delimiter=None, name=None)[source]#
The Repeat class is a node variable that represents a sequence of the same variable. This denotes an n-time repetition of a variable, which can be a terminal leaf or a non-terminal node.
The Repeat constructor expects some parameters:
- Parameters
child (
Variable, required) – The variable element that will be repeated.nbRepeat (an
intor atupleofintor a Python variable containing anintor aFieldor aCallable, required) – The number of repetitions of the element. This value can be a fixed integer, a tuple of integers defining the minimum and maximum of permitted repetitions, a constant from the calling script, a value present in another field, or can be identified by calling a callback function. In the latter case, the callback function should return a boolean telling if the expected number of repetitions is reached. Those use cases are described below.delimiter (
bitarray, optional) – The delimiter used to separate the repeated element. The default is None.name (
str, optional) – The name of the variable (if None, the name will be generated).
The Repeat class provides the following public variables:
- Variables
children (a list of
Variable) – The list of one element which is the child attached to the variable node.
Callback prototype
The callback function that can be used in the
nbRepeatparameter has the following prototype:- cbk_nbRepeat(nb_repeat, data, path, child, remaining)
- Parameters
nb_repeat (int) – the number of times the child element has been parsed or specialized.
data (bitarray) – the already parsed or specialized data.
path (object) – data structure that allows access to the values of the parsed
Variableelements.child (
Variable) – the repeated element.remaining (bitarray) – the remaining data to be parsed. Only set in parsing mode. In specialization mode, this parameter will have a
Nonevalue. This parameter can therefore be used to identify the current mode.
- Returns
The callback function should return one of the following values:
RepeatResult.CONTINUE: this tells to continue the repetition.RepeatResult.STOP_BEFORE: this tells to stop the repetition before the current value of the child.RepeatResult.STOP_AFTER: this tells to stop the repetition after the current value of the child.
- Return type
int
The
childis aVariable. Thechildcan have children if it is a node. Access to child values, as well as to its own children values, is done through thepathdata structure, thanks to its methodshasData()andgetData(). Those methods therefore allow access to a hierarchy of elements for which thechildis the root element:path.hasData(element)will return abooltelling if a data has been specialized or parsed for the elementVariable.path.getData(element)will return abitarraythat corresponds to the value specialized or parsed for the elementVariable.
It is possible to test if a
childvariable is a node of the tree structure through theisnode(child)method. A node may represent anAgg, anAlt, aRepeator anOptvariable. Access to the node leafs is possible with the attributechildren(i.e.child.children). The type of the children leafs is alsoVariable.The callback function is called each time the child element is seen.
Basic usage of Repeat
The following example shows a repeat variable where the repeated element is a String:
>>> from netzob.all import * >>> f1 = Field(Repeat(String("A"), nbRepeat=16)) >>> next(f1.specialize()) b'AAAAAAAAAAAAAAAA'
Limiting the number of repetitions with an integer
The following example shows how to create a Repeat variable whose number of repetitions is limited by an integer:
>>> from netzob.all import * >>> f1 = Field(Repeat(String("john"), nbRepeat=3))
Limiting the number of repetitions with an interval of integers
The following example shows how to create a Repeat variable whose number of repetitions is limited by an interval of integers:
>>> from netzob.all import * >>> f1 = Field(Repeat(String("john"), nbRepeat=(2,5)))
Limiting the number of repetitions with a Python integer variable
The following example shows how to create a Repeat variable whose number of repetitions is limited by a Python integer variable. Such a variable is typically managed by the calling script:
>>> from netzob.all import * >>> var = 3 >>> f1 = Field(Repeat(String("john"), nbRepeat=var))
Usage of a delimiter in Repeat
We can specify a delimiter between each repeated element, as depicted in the following example:
>>> from netzob.all import * >>> delimiter = bitarray(endian='big') >>> delimiter.frombytes(b"-") >>> f = Field(Repeat(Alt([String("A"), String("B")]), nbRepeat=(2, 4), ... delimiter=delimiter), name='f1') >>> next(f.specialize()) b'B-A-A'
Limiting the number of repetitions with the value of another field
The following example shows how to create a Repeat variable whose number of repetitions is limited by the value of another field:
>>> from netzob.all import * >>> f_nb = Field(Integer(interval=(2, 5))) >>> f_pattern = Field(Repeat(String("john"), nbRepeat=f_nb)) >>> f_header = Field([f_nb, f_pattern]) >>> next(f_header.specialize()) b'\x00\x05johnjohnjohnjohnjohn'
Limiting the number of repetitions by calling a callback function
The following example shows how to create a Repeat variable whose number of repetitions is handled by calling a callback function telling if the expected number of repetitions is reached. Here, in parsing mode, the repeat stops when the b’B’ byte is encountered. In specialization mode, the repeat stops at the first iteration.
>>> from netzob.all import * >>> def cbk(nb_repeat, data, path, child, remaining=None): ... if remaining is not None: # This means we are in parsing mode ... print("in cbk: nb_repeat:{} -- data:{} -- remaining:{}".format(nb_repeat, data.tobytes(), remaining.tobytes())) ... ... # We check the value of the second child of the parameter child ... if child.isnode() and len(child.children) > 1: ... second_subchild = child.children[1] ... if path.hasData(second_subchild) and path.getData(second_subchild).tobytes() == b'B': ... return RepeatResult.STOP_BEFORE ... return RepeatResult.CONTINUE ... return RepeatResult.STOP_AFTER >>> f1 = Field(Repeat(Alt([String("A"), String("B")]), nbRepeat=cbk), name="f1") >>> f2 = Field(String("B"), name="f2") >>> f3 = Field(String("C"), name="f3") >>> f = Field([f1, f2, f3]) >>> d = next(f.specialize()) >>> d == b'ABC' or d == b'BBC' True >>> data = "AABC" >>> f.abstract(data) in cbk: nb_repeat:1 -- data:b'A' -- remaining:b'ABC' in cbk: nb_repeat:2 -- data:b'AA' -- remaining:b'BC' in cbk: nb_repeat:3 -- data:b'AAB' -- remaining:b'C' OrderedDict([('f1', b'AA'), ('f2', b'B'), ('f3', b'C')])
Abstraction of repeat variables
The following examples show how repeat variable can be parsed:
>>> from netzob.all import * >>> f1 = Field(Repeat(String("john"), nbRepeat=(0,3)), name="f1") >>> f2 = Field(String("kurt"), name="f2") >>> s = Symbol([f1, f2]) >>> data = "johnkurt" >>> s.abstract(data) OrderedDict([('f1', b'john'), ('f2', b'kurt')]) >>> data = "kurt" >>> s.abstract(data) OrderedDict([('f1', b''), ('f2', b'kurt')])
Specialization of repeat variables
The following examples show how repeat variable can be specialized:
>>> from netzob.all import * >>> f1 = Field(Repeat(String("john"), nbRepeat=2)) >>> s = Symbol([f1]) >>> next(s.specialize()) b'johnjohn' >>> from netzob.all import * >>> delimiter = bitarray(endian='big') >>> delimiter.frombytes(b";") >>> f1 = Field(Repeat(IPv4(), nbRepeat=3, ... delimiter=delimiter)) >>> s = Symbol([f1]) >>> gen = next(s.specialize()) >>> len(gen) == 14 True >>> gen.count(b";") >= 2 True
>>> from netzob.all import * >>> delimiter = bitarray(endian='big') >>> delimiter.frombytes(b";") >>> child = Data(dataType=String(nbChars=(5))) >>> f1 = Field(Repeat(child, nbRepeat=3, ... delimiter=delimiter)) >>> s = Symbol([f1]) >>> gen = next(s.specialize()) >>> len(gen) == 17 True >>> gen.count(b";") >= 2 True
Optional Domain#
In the API, the definition of a conditional variable is made through the Opt class.
- class Opt(child, name=None)[source]#
The Opt class is a node variable that represents a variable that may or may not produce a value, either in abstraction or specialization.
The Opt constructor expects some parameters:
- Parameters
child (
Variable, required) – The optional variable element.name (
str, optional) – The name of the variable (if None, the name will be generated).
The following code shows an example of the Opt usage.
>>> from netzob.all import * >>> f0 = Field(String("a"), "f0") >>> f1 = Field(Opt(String("b")), "f1") >>> assert next(Symbol([f0, f1]).specialize()) in (b"a", b"ab")
Modeling Fields with Relationship Variables#
The ZDL language defines constraints on variables, in order to handle relationships. Those constraints are leveraged during abstraction and specialization of messages. The API supports the following relationships.
Value Relationships#
In the API, the definition of a relationship with the value of another field is made through the Value class. This class enables the computation of the relationship result by a basic copy of the targeted field or by calling a callback function.
- class Value(target, name=None, operation=None)[source]#
The Value class is a variable whose content is the value of another field.
It is possible to define a field so that its value is equal to the value of another field, on which an operation can be performed.
The Value constructor expects some parameters:
- Parameters
target (
FieldorVariable, required) – The targeted object of the relationship. If aFieldis provided, it will be normalized by the associatedVariable.name (
str, optional) – The name of the variable. If None, the name will be generated.operation (
Callable, optional) – An optional transformation operation to be applied to the targeted field value, through a callback. The default is None.
The Value class provides the following public variables:
- Variables
target (
Variable) – The variable that is required before computing the value of this relation.operation (
Callable) – Defines the operation to be performed on the found value. The prototype of this callback is detailed below.
Callback prototype
The callback function that can be used to specify a complex relationship in the
operationparameter has the following prototype:- cbk_operation(data, path, variable)
- Parameters
- Returns
The callback function should return a
bitarrayrepresenting the computed data during specialization or abstraction. In the latter case, if the callback function does not succeed to parse the data, it should return theNonevalue. The length of the computed data may differ from the length of the targeted data.- Return type
bitarray
Access to
Variablevalues is done through thepath, thanks to its methodshasData()andgetData():path.hasData(variable)will return abooltelling if a data has been specialized or parsed for the Value variableVariable.path.getData(variable)will return abitarraythat corresponds to the data specialized or parsed for the Value variableVariable.
The callback function is expected to implement relationship operations based on the provided data.
Value usage
The following example shows how to define a field with a copy of another field value, in specialization mode:
>>> from netzob.all import * >>> f0 = Field(String("abcd")) >>> f1 = Field(Value(f0)) >>> fheader = Field([f0, f1]) >>> next(fheader.specialize()) b'abcdabcd'
The following example shows how to define a field with a copy of another field value, in abstraction mode:
>>> from netzob.all import * >>> data = "john;john!" >>> f1 = Field(String(nbChars=(2, 8)), name="f1") >>> f2 = Field(String(";"), name="f2") >>> f3 = Field(Value(f1), name="f3") >>> f4 = Field(String("!"), name="f4") >>> s = Symbol(fields=[f1, f2, f3, f4]) >>> s.abstract(data) OrderedDict([('f1', b'john'), ('f2', b';'), ('f3', b'john'), ('f4', b'!')])
Value field with a variable as a target
The following example shows the specialization process of a Value field whose target is a variable:
>>> from netzob.all import * >>> d = Data(String("john")) >>> f1 = Field(domain=d, name="f1") >>> f2 = Field(String(";"), name="f2") >>> f3 = Field(Value(d), name="f3") >>> f4 = Field(String("!"), name="f4") >>> f = Field([f1, f2, f3, f4]) >>> next(f.specialize()) b'john;john!'
Specialization of Value objects
The following examples show the specialization process of Value objects. The first example illustrates a case where the Value variable is placed before the targeted variable.
>>> from netzob.all import * >>> f1 = Field(String("john"), name="f1") >>> f2 = Field(String(";"), name="f2") >>> f3 = Field(Value(f1), name="f3") >>> f4 = Field(String("!"), name="f4") >>> f = Field([f1, f2, f3, f4]) >>> next(f.specialize()) b'john;john!'
The second example illustrates a case where the Value variable is placed after the targeted variable.
>>> from netzob.all import * >>> f3 = Field(String("john"), name="f3") >>> f2 = Field(String(";"), name="f2") >>> f1 = Field(Value(f3), name="f1") >>> f4 = Field(String("!"), name="f4") >>> f = Field([f1, f2, f3, f4]) >>> next(f.specialize()) b'john;john!'
Transformation operation on targeted field value
A named callback function can be used to specify a more complex relationship. The following example shows a relationship where the computed value corresponds to the reversed bits of the targeted field value. The
dataparameter of thecbkfunction contains a bitarray object of the targeted field value. Thecbkfunction returns a bitarray object.>>> from netzob.all import * >>> def cbk(data, path, value): ... ret = data.copy() ... ret.reverse() ... if ret == bitarray('10000000'): ... return ret ... else: ... return None >>> f0 = Field(Raw(b'\x01'), name='f0') >>> f1 = Field(Value(f0, operation = cbk), name='f1') >>> f = Field([f0, f1], name='f') >>> data = next(f.specialize()) >>> data b'\x01\x80'
Callback functions are also triggered during data abstraction. In the next portion of the example, the previously specialized data is abstracted according to the field definition.
>>> f.abstract(data) OrderedDict([('f0', b'\x01'), ('f1', b'\x80')])
If the targeted field (
f0) does not contain the expected data, the callback function should returnNone, indicating that the relationship does not apply. In this case, the abstraction process will return an exception.>>> data = b'\x02\x80' >>> f.abstract(data) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.AbstractionException: With the symbol/field 'f', cannot abstract the data: 'b'\x02\x80''. Error: 'No parsing path returned while parsing 'b'\x02\x80'''
Size Relationships#
- class Size(targets, dataType=None, factor=0.125, offset=0, name=None)[source]#
The Size class is a variable whose content is the size of other field values.
It is possible to define a field so that its value is equal to the size of another field, or group of fields (potentially including itself).
By default, the computed size expresses an amount of bytes. It is possible to change this behavior by using the
factorandoffsetparameters.The Size constructor expects some parameters:
- Parameters
targets (a
Fieldor aVariableor alistofFieldorVariable, required) – The targeted objects of the relationship. If aFieldis provided, it will be normalized by the associatedVariable.dataType (
AbstractType, optional) – Specify that the produced value should be represented according to this dataType. If None, default value is Raw(nbBytes=1).factor (
float, optional) – Specify that the initial size value (always expressed in bits) should be multiplied by this factor. The default value is1.0/8. For example, to express a size in bytes, the factor should be1.0/8, whereas to express a size in bits, the factor should be1.0.offset (
int, optional) – Specify that an offset value should be added to the final size value (after applying the factor parameter). The default value is 0.name (
str, optional) – The name of the variable. If None, the name will be generated.
The Size class provides the following public variables:
- Variables
targets (a list of
Variable) – The list of variables that are required before computing the value of this relationdataType (
AbstractType) – The type of the data.factor (
float) – Defines the multiplication factor to apply to the targeted length.offset (
int) – Defines the offset to apply to the computed length.
The following example shows how to define a size field with a Raw dataType:
>>> from netzob.all import * >>> f0 = Field(String(nbChars=10)) >>> f1 = Field(String(";")) >>> f2 = Field(Size([f0], dataType=Raw(nbBytes=1))) >>> f = Field([f0, f1, f2]) >>> data = next(f.specialize()) >>> data[-1] == 10 True
The following example shows how to define a size field with a Raw dataType, along with specifying the
factorandoffsetparameters.>>> from netzob.all import * >>> f0 = Field(String(nbChars=(4,10))) >>> f1 = Field(String(";")) >>> f2 = Field(Size([f0, f1], dataType=Raw(nbBytes=1), factor=1./8, offset=4)) >>> f = Field([f0, f1, f2]) >>> data = next(f.specialize()) >>> data[-1] > (4*8*1./8 + 4) # == 4 bytes minimum * 8 bits * a factor of 1./8 + an offset of 4 True
In this example, the f2 field is a size field where its value is equal to the size of the concatenated values of fields f0 and f1. The dataType parameter specifies that the produced value should be represented as a
Raw. The factor parameter specifies that the initial size value (always expressed in bits) should be multiplied by1.0/8(in order to retrieve the amount of bytes). The offset parameter specifies that the final size value should be computed by adding 4 bytes.The following example shows how to define a size field so that its value depends on a list of non-consecutive fields:
>>> from netzob.all import * >>> f1 = Field(String("=")) >>> f2 = Field(String("#")) >>> f4 = Field(String("%")) >>> f5 = Field(Raw(b"_")) >>> f3 = Field(Size([f1, f2, f4, f5])) >>> f = Field([f1, f2, f3, f4, f5]) >>> next(f.specialize()) b'=#\x04%_'
In the following example, a size field is declared after its targeted field. This shows that the field order does not impact the relationship computations.
>>> from netzob.all import * >>> f0 = Field(String(nbChars=(1,4)), name='f0') >>> f1 = Field(String(";"), name='f1') >>> f2 = Field(Size(f0), name='f2') >>> f = Field([f0, f1, f2]) >>> 3 <= len(next(f.specialize())) <= 6 True
In the following example, a size field is declared before the targeted field:
>>> from netzob.all import * >>> f2 = Field(String(nbChars=(1,4)), name="f2") >>> f1 = Field(String(";"), name="f1", ) >>> f0 = Field(Size(f2), name="f0") >>> f = Field([f0, f1, f2]) >>> d = next(f.specialize()) >>> 3 <= len(d) <= 6 True
Size field with fields and variables as target
The following examples show the specialization process of a Size field whose targets are both fields and variables:
>>> from netzob.all import * >>> d = Data(String(nbChars=20)) >>> f0 = Field(domain=d) >>> f1 = Field(String(";")) >>> f2 = Field(Size([d, f1])) >>> f = Field([f0, f1, f2]) >>> res = next(f.specialize()) >>> b'\x15' in res True
>>> from netzob.all import * >>> d = Data(String(nbChars=20)) >>> f2 = Field(domain=d) >>> f1 = Field(String(";")) >>> f0 = Field(Size([f1, d])) >>> f = Field([f0, f1, f2]) >>> res = next(f.specialize()) >>> b'\x15' in res True
Size field which targets itself
The following example shows a Size field whose targets contain itsef. In such case, the domain datatype (here, an
uint16) is used to compute the size of the length field (here, the datatype occupies 2 bytes).>>> from netzob.all import * >>> f0 = Field(uint8(0), name="f0") >>> f1 = Field(uint8(0), name="f1") >>> f2 = Field(name="len") >>> f3 = Field(uint32(0), name="f3") >>> f4 = Field(Raw(nbBytes=(0,28)), name="f4") >>> f2.domain = Size([f0, f1, f2, f3, f4], dataType=uint16()) >>> symbol = Symbol([f0, f1, f2, f3, f4]) >>> data = next(symbol.specialize()) >>> data b'\x00\x00\x00\x15\x00\x00\x00\x00z\x12\x10\xfe\x9a$)L\xc4\xbfL91' >>> symbol.abstract(data) OrderedDict([('f0', b'\x00'), ('f1', b'\x00'), ('len', b'\x00\x15'), ('f3', b'\x00\x00\x00\x00'), ('f4', b'z\x12\x10\xfe\x9a$)L\xc4\xbfL91')])
Padding Relationships#
In the API, it is possible to model a structure with a padding through the Padding class.
- class Padding(targets, data, modulo, once=False, factor=1.0, offset=0, name=None)[source]#
The Padding class is a variable whose content makes it possible to produce a padding value that can be used to align a structure to a fixed size.
The Padding constructor expects some parameters:
- Parameters
targets (a
Fieldor aVariableor alistofFieldorVariable, required) – The targeted objects of the relationship. If aFieldis provided, it will be normalized by the associatedVariable.data (a
AbstractTypeor aCallable, required) – Specify that the produced value should be represented according to this data. A callback function, returning the padding value, can be used here.modulo (
int, required) – Specify the expected modulo size. The padding value will be computed so that the whole structure aligns to this value. This typically corresponds to a block size in cryptography.once (
bool, optional) – If True, the padding is applied only if the total size of the targeted fields is smaller than the modulo value. Default value isFalse.factor (
float, optional) – Specify that the length of the targeted structure (always expressed in bits) should be multiplied by this factor. The default value is1.0. For example, to express a length in bytes, the factor should be1.0/8, whereas to express a length in bits, the factor should be1.0.offset (
int, optional) – Specify a value in bits that should be added to the length of the targeted structure (after applying the factor parameter). The default value is 0.name (
str, optional) – The name of the variable. If None, the name will be generated.
The Padding class provides the following public variables:
- Variables
targets (a list of
Variable) – The list of variables that are required before computing the value of this relationdataType (
AbstractType) – The type of the data.factor (
float) – Defines the multiplication factor to apply to the targeted length.offset (
int) – Defines the offset to apply to the computed length.
Callback prototype
The callback function that can be used in the
dataparameter to specify the padding value has the following prototype:- cbk_data(current_length, modulo)
- Parameters
current_length (
int) – corresponds to the current size in bits of the targeted structure.modulo (
int) – corresponds to the expected modulo size in bits.
- Returns
The callback function should return a
bitarray.- Return type
bitarray
Padding examples
The following code illustrates a padding with a modulo integer. Here, the padding data
b'\x00'is repeatedntimes, wherenis computed by decrementing the modulo number,128, by the current length of the targeted structure. The padding length is therefore equal to128 - (10+2)*8 = 32bits.>>> from netzob.all import * >>> f0 = Field(Raw(nbBytes=10)) >>> f1 = Field(Raw(b"##")) >>> f2 = Field(Padding([f0, f1], data=Raw(b'\x00'), modulo=128)) >>> f = Field([f0, f1, f2]) >>> d = next(f.specialize()) >>> d[12:] b'\x00\x00\x00\x00' >>> len(d) * 8 128
The following code illustrates a padding with the use of the
offsetparameter, where the targeted field sizes are decremented by 8 when computing the padding value length.>>> from netzob.all import * >>> f0 = Field(Raw(nbBytes=10)) >>> f1 = Field(Raw(b"##")) >>> f2 = Field(Padding([f0, f1], data=Raw(b'\x00'), modulo=128, offset=8)) >>> f = Field([f0, f1, f2]) >>> d = next(f.specialize()) >>> d[12:] b'\x00\x00\x00' >>> len(d) * 8 120
The following code illustrates a padding with the use of the
factorparameter, where the targeted field sizes are multiplied by1.0/2before computing the padding value length.>>> from netzob.all import * >>> f0 = Field(Raw(nbBytes=10)) >>> f1 = Field(Raw(b"##")) >>> f2 = Field(Padding([f0, f1], data=Raw(b'\x00'), modulo=128, factor=1./2)) >>> f = Field([f0, f1, f2]) >>> d = next(f.specialize()) >>> d[12:] b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' >>> len(d) * 8 256
The following code illustrates a padding with the use of a callback function that helps to determine the padding value. In this example, the padding value is an incrementing integer.
>>> from netzob.all import * >>> f0 = Field(Raw(nbBytes=10)) >>> f1 = Field(Raw(b"##")) >>> def cbk_data(current_length, modulo): ... length_to_pad = modulo - (current_length % modulo) # Length in bits ... length_to_pad = int(length_to_pad / 8) # Length in bytes ... res_bytes = b"".join([t.to_bytes(1, byteorder='big') for t in list(range(length_to_pad))]) ... res_bits = bitarray() ... res_bits.frombytes(res_bytes) ... return res_bits >>> f2 = Field(Padding([f0, f1], data=cbk_data, modulo=128)) >>> f = Field([f0, f1, f2]) >>> d = next(f.specialize()) >>> d[12:] b'\x00\x01\x02\x03' >>> len(d) * 8 128
The following code illustrates a padding with the use of a callback function that helps to determine the padding value. In this example, the padding value is a repetition of an incrementing integer, thus implementing the PKCS #7 padding.
>>> from netzob.all import * >>> f0 = Field(Raw(nbBytes=10)) >>> f1 = Field(Raw(b"##")) >>> def cbk_data(current_length, modulo): ... length_to_pad = modulo - (current_length % modulo) # Length in bits ... length_to_pad = int(length_to_pad / 8) # Length in bytes ... res_bytes = b"".join([int(length_to_pad).to_bytes(1, byteorder='big') * length_to_pad]) ... res_bits = bitarray() ... res_bits.frombytes(res_bytes) ... return res_bits >>> f2 = Field(Padding([f0, f1], data=cbk_data, modulo=128)) >>> f = Field([f0, f1, f2]) >>> d = next(f.specialize()) >>> d[12:] b'\x04\x04\x04\x04' >>> len(d) * 8 128
Checksum Relationships#
The ZDL language enables the definition of checksum relationships between fields.
Checksum API
As an example, the API for the CRC16 checksum is as follows:
- class CRC16(targets)[source]#
This class implements the CRC16 function.
The constructor expects some parameters:
- Parameters
targets (a
listofField, required) – The targeted fields of the relationship.
The following example shows how to create a checksum relationship with another field:
>>> from netzob.all import * >>> import binascii >>> f1 = Field(Raw(b'\xaa\xbb')) >>> f2 = Field(CRC16([f1])) >>> f = Field([f1, f2]) >>> binascii.hexlify(next(f.specialize())) b'aabb3ed3'
The following example shows how to create a checksum relationship with a group of fields:
>>> from netzob.all import * >>> import binascii >>> f1 = Field(Raw(b'\xaa\xbb')) >>> f2 = Field(Raw(b'\xcc\xdd')) >>> f3 = Field(Raw(b'\xee\xff')) >>> f4 = Field(CRC16([f1, f2, f3])) >>> f = Field([f1, f2, f3, f4]) >>> binascii.hexlify(next(f.specialize())) b'aabbccddeeff5e9b'
- copy()#
Copy the current object as well as all its dependencies.
- Returns
A new object of the same type.
- Return type
AbstractChecksum
Available checksums
The following list shows the available checksums. The API for those checksums are similar to the CRC16 API.
CRC16DNP(targets)CRC16Kermit(targets)CRC16SICK(targets)CRC32(targets)CRCCCITT(targets)InternetChecksum(targets)(used in ICMP, UDP, IP, TCP protocols, as specified in RFC 1071).
Hash Relationships#
The ZDL language enables the definition of hash relationships between fields.
Hash API
As an example, the API for the MD5 hash is as follows:
- class MD5(targets)[source]#
This class implements the MD5 relationships between fields.
The constructor expects some parameters:
- Parameters
targets (a
listofField, required) – The targeted fields of the relationship.
The following example shows how to create a hash relation with another field:
>>> from netzob.all import * >>> import binascii >>> f1 = Field(Raw(b'\xaa\xbb')) >>> f2 = Field(MD5([f1])) >>> f = Field([f1, f2]) >>> binascii.hexlify(next(f.specialize())) b'aabb58cea1f6b2b06520613e09af90dc1c47'
- copy()#
Copy the current object as well as all its dependencies.
- Returns
A new object of the same type.
- Return type
AbstractHash
Available hashes
The following list shows the available hashes. The API for those hashes are similar to the MD5 API.
SHA1(targets)SHA1_96(targets)SHA2_224(targets)SHA2_256(targets)SHA2_384(targets)SHA2_512(targets)
HMAC Relationships#
The ZDL language enables the definition of HMAC relationships between fields.
HMAC API
As an example, the API for the HMAC_MD5 is as follows:
- class HMAC_MD5(targets, key)[source]#
This class implements the HMAC_MD5.
The constructor expects some parameters:
- Parameters
targets (a
listofField, required) – The targeted fields of the relationship.key (
bytes, required) – The cryptographic key used in the hmac computation.
The following example shows how to create a HMAC relation with another field:
>>> from netzob.all import * >>> import binascii >>> f1 = Field(Raw(b'\xaa\xbb')) >>> f2 = Field(HMAC_MD5([f1], key=b'1234')) >>> f = Field([f1, f2]) >>> binascii.hexlify(next(f.specialize())) b'aabbb71c98baa40dc8a49361816d5dc1eb25'
- copy()#
Copy the current object as well as all its dependencies.
- Returns
A new object of the same type.
- Return type
AbstractHMAC
Available HMACs
The following list shows the available HMACs. The API for those HMACs are similar to the HMAC_MD5 API.
HMAC_SHA1(targets, key)HMAC_SHA1_96(targets, key)HMAC_SHA2_224(targets, key)HMAC_SHA2_256(targets, key)HMAC_SHA2_384(targets, key)HMAC_SHA2_512(targets, key)
Modeling Symbols#
In the API, symbol modeling is done through the Symbol class.
- class Symbol(fields: Optional[List[netzob.Model.Vocabulary.Field.Field]] = None, messages: Optional[List[netzob.Model.Vocabulary.Messages.AbstractMessage.AbstractMessage]] = None, name: str = 'Symbol')[source]#
The Symbol class is a main component of the Netzob protocol model.
A symbol represents an abstraction of all messages of the same type from a protocol perspective. A symbol structure is made of fields.
The Symbol constructor expects some parameters:
- Parameters
fields (a
listofField, optional) – The fields that participate in the symbol definition, in the wire order. May beNone(thus, a genericFieldinstance would be defined), especially when using Symbols for reverse engineering (i.e. fields identification).messages (a
listofAbstractMessage, optional) – The messages that are associated with the symbol. May beNone(thus, an emptylistwould be defined), especially when modeling a protocol from scratch (i.e. the fields are already known).name (
str, optional) – The name of the symbol. If not specified, the default name will be “Symbol”.
The Symbol class provides the following public variables:
- Variables
fields (a
listofField) – The sorted list of sub-fields.name (
str) – The name of the symbol.description (
str) – The description of the symbol.
Usage of Symbol for protocol modeling
The Symbol class may be used to model a protocol from scratch, by specifying its structure in terms of fields:
>>> from netzob.all import * >>> f0 = Field("aaaa") >>> f1 = Field(" # ") >>> f2 = Field("bbbbbb") >>> symbol = Symbol(fields=[f0, f1, f2]) >>> for f in symbol.fields: ... print("{} - {}".format(f, f.domain)) Field - Data (String('aaaa')) Field - Data (String(' # ')) Field - Data (String('bbbbbb'))
Usage of Symbol for protocol dissecting
The Symbol class may be used to dissect a list of messages according to the fields structure:
>>> from netzob.all import * >>> f0 = Field("hello", name="f0") >>> f1 = Field(String(nbChars=(0, 10)), name="f1") >>> m1 = RawMessage("hello world") >>> m2 = RawMessage("hello earth") >>> symbol = Symbol(fields=[f0, f1], messages=[m1, m2]) >>> print(symbol.str_data()) f0 | f1 ------- | -------- 'hello' | ' world' 'hello' | ' earth' ------- | --------
Usage of Symbol for protocol reverse engineering
The Symbol class may be used is to do reverse engineering on a list of captured messages of unknown/undocumented protocols:
>>> from netzob.all import * >>> m1 = RawMessage("hello aaaa") >>> m2 = RawMessage("hello bbbb") >>> symbol = Symbol(messages=[m1, m2]) >>> Format.splitStatic(symbol) >>> print(symbol.str_data()) Field-0 | Field-1 -------- | ------- 'hello ' | 'aaaa' 'hello ' | 'bbbb' -------- | -------
- copy()[source]#
Copy the current object as well as all its dependencies. This method returns a new object of the same type.
- Returns
A new object of the same type.
- Return type
- str_structure(preset=None)[source]#
Returns a string which denotes the current symbol definition using a tree display.
- Parameters
preset (
Preset, optional) – The configuration used to parameterize values in fields and variables.- Returns
The current symbol represented as a string.
- Return type
str
This example shows the rendering of a symbol with multiple fields.
>>> from netzob.all import * >>> f1 = Field(String(), name="field1") >>> f2 = Field(Integer(interval=(10, 100)), name="field2") >>> f3 = Field(Raw(nbBytes=14), name="field3") >>> symbol = Symbol([f1, f2, f3], name="symbol_name") >>> print(symbol.str_structure()) symbol_name |-- field1 |-- Data (String(nbChars=(0,8192))) |-- field2 |-- Data (Integer(10,100)) |-- field3 |-- Data (Raw(nbBytes=14)) >>> print(f1.str_structure()) field1 |-- Data (String(nbChars=(0,8192)))
This example shows the rendering of a symbol where a Preset configuration has been applied on several variables (the
fuzz()method is explained in the fuzzing section).>>> from netzob.all import * >>> field1 = Field(Raw(nbBytes=1), name="field 1") >>> v1 = Data(uint8(), name='v1') >>> v2 = Data(uint8()) >>> var_agg = Agg([v1, v2]) >>> field2 = Field(var_agg, name="field 2") >>> field3 = Field(Raw(nbBytes=1), name="field 3") >>> symbol = Symbol(name="symbol 1", fields=[field1, field2, field3]) >>> preset = Preset(symbol) >>> preset[field1] = b'\x42' >>> preset.fuzz('v1', mode=FuzzingMode.MUTATE) >>> preset.fuzz(field3) >>> print(symbol.str_structure(preset)) symbol 1 |-- field 1 |-- Data (Raw(nbBytes=1)) [FuzzingMode.FIXED (b'B')] |-- field 2 |-- Agg |-- Data (Integer(0,255)) [FuzzingMode.MUTATE] |-- Data (Integer(0,255)) |-- field 3 |-- Data (Raw(nbBytes=1)) [FuzzingMode.GENERATE]
- abstract(data, preset=None, memory=None)#
The
abstract()method is used to abstract the given data bytes with the current symbol (or field) model. This method also works on fields, in order to abstract abytesinto a field object.Similarly to the
specialize()method, it is possible to indicate a Preset configuration that will be used to check content parsed for specific fields. However, for theabstract()method, it is only possible to specify field names for keys of the Preset configuration. The reason of this restriction is that theabstract()method returns anOrderedDictcontaining also field names as keys.The
abstract()method expects some parameters:- Parameters
data (
bytes, required) – The concrete message to abstract in symbol (or field).preset (
Preset, optional) – The configuration used to check values in symbol (or field) structure obtained after message parsing.memory (
Memory, optional) – A memory used to store variable values during specialization and abstraction of sequence of symbols (or fields). The default value is None.
- Returns
The structure of the parsed data.
- Return type
An
OrderedDictwhere keys arestrand values arebytes- Raises
AbstractionExceptionif an error occurs while abstracting the data
Note
When using the
abstract()method, it is important to explicitly name all the fields with different names, because the resulting OrderedDict will use field names as its keys.Abstracting data into a field
The following code shows an example of abstracting a data according to a field definition:
>>> from netzob.all import * >>> messages = ["john, what's up in {} ?".format(city) ... for city in ['Paris', 'Berlin']] >>> >>> f1a = Field(name="name", domain="john") >>> f2a = Field(name="question", domain=", what's up in ") >>> f3a = Field(name="city", domain=Alt(["Paris", "Berlin"])) >>> f4a = Field(name="mark", domain=" ?") >>> f = Field([f1a, f2a, f3a, f4a], name="field-john") >>> >>> for m in messages: ... structured_data = f.abstract(m) ... print(structured_data) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Paris'), ('mark', b' ?')]) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Berlin'), ('mark', b' ?')])
Abstracting data into a symbol
The following code shows an example of abstracting a data according to a symbol definition:
>>> from netzob.all import * >>> messages = ["john, what's up in {} ?".format(city) ... for city in ['Paris', 'Berlin']] >>> >>> f1a = Field(name="name", domain="john") >>> f2a = Field(name="question", domain=", what's up in ") >>> f3a = Field(name="city", domain=Alt(["Paris", "Berlin"])) >>> f4a = Field(name="mark", domain=" ?") >>> s = Symbol([f1a, f2a, f3a, f4a], name="Symbol-john") >>> >>> for m in messages: ... structured_data = s.abstract(m) ... print(structured_data) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Paris'), ('mark', b' ?')]) OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Berlin'), ('mark', b' ?')])
Usage of Symbol for traffic generation and parsing
A Symbol class may be used to generate concrete messages according to its field definition, through the
specialize()method, and may also be used to abstract a concrete message into its associated symbol through theabstract()method:>>> from netzob.all import * >>> f0 = Field("aaaa", name="f0") >>> f1 = Field(" # ", name="f1") >>> f2 = Field("bbbbbb", name="f2") >>> s = Symbol(fields=[f0, f1, f2]) >>> concrete_message = next(s.specialize()) >>> concrete_message b'aaaa # bbbbbb' >>> s.abstract(concrete_message) OrderedDict([('f0', b'aaaa'), ('f1', b' # '), ('f2', b'bbbbbb')])
Usage of Preset during message abstraction
The following code shows an example of abstracting a data according to a symbol definition and a defined Preset configuration:
>>> from netzob.all import * >>> >>> f1 = Field(name="name", domain="john") >>> f2 = Field(name="question", domain=", what's up in ") >>> f3 = Field(name="city", domain=Alt(["Paris", "Berlin"])) >>> f4 = Field(name="mark", domain=" ?") >>> symbol = Symbol([f1, f2, f3, f4], name="Symbol-john") >>> >>> # We build a Preset configuration indicating that we expect "Paris" for the field f3 >>> preset = Preset(symbol) >>> preset[f3] = b"Paris" >>> >>> data = "john, what's up in Berlin ?" >>> data_structure = symbol.abstract(data, preset=preset) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.AbstractionException: With the symbol/field 'Symbol-john', can abstract the data: 'john, what's up in Berlin ?', but some parsed values do not match the expected preset. >>> >>> data = "john, what's up in Paris ?" >>> data_structure = symbol.abstract(data, preset=preset) >>> >>> data_structure OrderedDict([('name', b'john'), ('question', b", what's up in "), ('city', b'Paris'), ('mark', b' ?')])
- count(preset=None)[source]#
The
count()method computes the expected number of unique messages produced, considering the initial symbol model and the preset configuration of fields.The
count()method expects the following parameters:- Parameters
preset (
Preset, optional) – The configuration used to parameterize values in fields and variables. This configuration will impact the expected number of unique messages the symbol would produce.- Returns
The number of unique values the symbol specialization can produce.
- Return type
int
Note
The theoretical value returned by
count()may be huge. Therefore, we force the returned value to beMAXIMUM_POSSIBLE_VALUES(86400000000), if the theoretical result is beyond this threshold. This limit corresponds to 1 day of data generation based on a generation bandwith of 1 million per second.>>> # Symbol definition >>> from netzob.all import * >>> from netzob.Fuzzing.Generators.DeterministGenerator import DeterministGenerator >>> f1 = Field(uint16(interval=(50, 1000))) >>> f2 = Field(uint8()) >>> f3 = Field(uint8()) >>> symbol = Symbol(fields=[f1, f2, f3]) >>> >>> # Count the expected number of unique produced messages >>> symbol.count() # Here, the following computation is done: 951*256*256 (f1 is able to produce 1000-50+1=951 possible values, based on its interval) 62324736 >>> >>> # Specify a preset configuration for field 'f2' >>> preset = Preset(symbol) >>> preset[f2] = 42 >>> symbol.count(preset) # Here, the following computation is done: 951*1*256 (as the f2 field value is set to 42, f2 can now produce only 1 possible value) 243456 >>> >>> # Specify a preset configuration for field 'f3' by activating fuzzing >>> preset.fuzz(f3, generator='determinist') >>> >>> symbol.count(preset) # Here, the following computation is done: 951*1*29 (29 corresponds to the number of possible values generated by the determinist generator) 27579
- getField(field_name)#
Retrieve a sub-field based on its name.
- Parameters
field_name (
str, required) – the name of theFieldobject- Returns
The sub-field object.
- Return type
Field- Raises
KeyError – when the field has not been found
The following example shows how to retrieve a sub-field based on its name:
>>> from netzob.all import * >>> f1 = Field("hello", name="f1") >>> f2 = Field("hello", name="f2") >>> f3 = Field("hello", name="f3") >>> fheader = Field(name="fheader") # create a Field named 'fheader' >>> fheader.fields = [f1, f2, f3] # this Field is parent of 3 existing Fields >>> type(fheader.getField('f2')) # get the sub-field named 'f2' <class 'netzob.Model.Vocabulary.Field.Field'> >>> >>> s = Symbol([f1, f2, f3]) >>> type(s.getField('f2')) # get the field named 'f2' in the symbol <class 'netzob.Model.Vocabulary.Field.Field'>
- specialize(preset=None, memory=None)[source]#
The
specialize()method is intended to produce concretebytesdata based on the symbol model and the currentPresetconfiguration. This method returns a Python generator that in turn provides databytesobject at each call tonext(generator).The specialize() method expects some parameters:
- Parameters
preset (
Preset, optional) – The configuration used to parameterize values in fields and variables.memory (
Memory, optional) – A memory used to store variable values during specialization and abstraction of successive symbols, especially to handle inter-symbol relationships. If None, a temporary memory is created by default and used internally during the scope of the specialization process.
- Returns
A generator that provides data
bytesat each call tonext(generator).- Return type
Generator[bytes]- Raises
GenerationExceptionif an error occurs while specializing the field.
The following example shows the
specialize()method used for a field which contains a String field and a Size field.>>> from netzob.all import * >>> f1 = Field(domain=String('hello')) >>> f2 = Field(domain=String(' ')) >>> f3 = Field(domain=String('John')) >>> s = Symbol(fields=[f1, f2, f3]) >>> next(s.specialize()) b'hello John'
Configuring Symbol Content#
Setting Field Values#
In the API, it is possible to control values that will be used in fields during symbol specialization. Such configuration can be done through the Preset class.
- class Preset(symbol, name='preset')[source]#
The Preset class is used to configure symbol specialization, by fixing the expected value of a field or a variable. The Preset component also works at the Field level, in the context of field specialization. The Preset class is also the component responsible for format message fuzzing (see below).
The Preset constructor expects some parameters:
- Parameters
The Preset works like a Python
dictwith a key:value principle:- Parameters
Note
You can only set (e.g.
preset[field] = b'\xaa\xbb') or unset (e.g.del preset[field]) a Preset configuration on a field or variable. However, it is not allowed to access an item of the Preset configuration (e.g.new_var = preset[field]).The different ways to specify a field to preset
It is possible to parameterize fields during symbol (or field) specialization. Values configured for fields will override any field definition, constraints or relationship dependencies.
The Preset configuration accepts a sequence of keys and values, where keys correspond to the fields or variables in the symbol that we want to override, and values correspond to the overriding content. Keys are either expressed as field/variable object or strings containing field/variable accessors when names are used (such as in
f = Field(name="udp.dport")). Values are either expressed asbitarray(as it is the internal type for variables in the Netzob library), asbytesor in the type associated with of the overridden field variable.The following code shows the definition of a simplified UDP header that will be later used as base example. This UDP header is made of one named field containing a destination port, and a named field containing a payload:
>>> from netzob.all import * >>> f_dport = Field(name="udp.dport", domain=Integer(unitSize=UnitSize.SIZE_8)) >>> f_payload = Field(name="udp.payload", domain=Raw(nbBytes=2)) >>> symbol_udp = Symbol(name="udp", fields=[f_dport, f_payload])
The four following codes show the same way to express the parameterized values during specialization of the
udp_dportandudp_payloadfields:>>> preset = Preset(symbol_udp) >>> preset[f_dport] = 11 # udp.dport expects an int or an Integer >>> preset[f_payload] = b"\xaa\xbb" # udp.payload expects a bytes object or a Raw object >>> next(symbol_udp.specialize(preset)) b'\x00\x0b\xaa\xbb'
>>> preset = Preset(symbol_udp) >>> preset["udp.dport"] = 11 # udp.dport expects an int or an Integer >>> preset["udp.payload"] = b"\xaa\xbb" # udp.payload expects a bytes object or a Raw object >>> next(symbol_udp.specialize(preset)) b'\x00\x0b\xaa\xbb'
>>> preset = Preset(symbol_udp) >>> preset["udp.dport"] = uint16(11) # udp.dport expects an int or an Integer >>> preset["udp.payload"] = Raw(b"\xaa\xbb") # udp.payload expects a bytes object or a Raw object >>> next(symbol_udp.specialize(preset)) b'\x00\x0b\xaa\xbb'
>>> preset = Preset(symbol_udp) >>> preset["udp.dport"] = bitarray('00001011', endian='big') >>> preset["udp.payload"] = bitarray('1010101010111011', endian='big') >>> next(symbol_udp.specialize(preset)) b'\x0b\xaa\xbb'
The previous example shows the use of BitArray as dict values. BitArray are always permitted for any parameterized field, as it is the internal type for variables in the Netzob library.
A preset value bypasses all the constraint checks on the field definition. In the following example, it is used to bypass a size field definition.
>>> from netzob.all import * >>> f1 = Field() >>> f2 = Field(domain=Raw(nbBytes=(10,15))) >>> f1.domain = Size(f2) >>> s = Symbol(fields=[f1, f2]) >>> preset = Preset(s) >>> preset[f1] = bitarray('11111111') >>> next(s.specialize(preset)) b'\xff\x10\xdb\xf7\x07i\xec\xfb\x8eR\x11\xfa\xa7&\x7f'
Fixing the value of a field
>>> from netzob.all import * >>> f1 = Field(uint8()) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> preset[f1] = b'\x41' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'A' >>> next(messages_gen) b'A' >>> next(messages_gen) b'A'
Fixing the value of a sub-field
>>> from netzob.all import * >>> f1 = Field(uint8()) >>> f2_1 = Field(uint8()) >>> f2_2 = Field(uint8()) >>> f2 = Field([f2_1, f2_2]) >>> symbol = Symbol([f1, f2], name="sym") >>> preset = Preset(symbol) >>> preset[f2_1] = b'\x41' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'\xb8A\x16' >>> next(messages_gen) b'\xb8A\xd7' >>> next(messages_gen) b'\xb8AG'
Fixing the value of a field that contains sub-fields
This should trigger an exception as it is only possible to fix a value to leaf fields.
>>> from netzob.all import * >>> f1 = Field(uint8()) >>> f2_1 = Field(uint8()) >>> f2_2 = Field(uint8()) >>> f2 = Field([f2_1, f2_2]) >>> symbol = Symbol([f1, f2], name="sym") >>> preset = Preset(symbol) >>> preset[f2] = b'\x41' Traceback (most recent call last): ... Exception: Cannot set a fixed value on a field that contains sub-fields
Fixing the value of a leaf variable
>>> from netzob.all import * >>> v1 = Data(uint8()) >>> v2 = Data(uint8()) >>> v_agg = Agg([v1, v2]) >>> f1 = Field(v_agg) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> preset[v1] = b'\x41' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'A\xb5' >>> next(messages_gen) b'A\xc3' >>> next(messages_gen) b'A\xd7'
Fixing the value of a node variable
>>> from netzob.all import * >>> v1 = Data(uint8()) >>> v2 = Data(uint8()) >>> v_agg = Agg([v1, v2]) >>> f1 = Field(v_agg) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> preset[v_agg] = b'\x41\x42\x43' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'ABC' >>> next(messages_gen) b'ABC' >>> next(messages_gen) b'ABC'
Fixing the value of a field, by relying on a provided generator
>>> from netzob.all import * >>> f1 = Field(uint8()) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> my_generator = (x for x in [b'\x41', b'\x42', b'\x43']) >>> preset[f1] = my_generator >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'A' >>> next(messages_gen) b'B' >>> next(messages_gen) b'C' >>> next(messages_gen) Traceback (most recent call last): ... RuntimeError: generator raised StopIteration
Fixing the value of a field, by relying on a provided iterator
>>> from netzob.all import * >>> f1 = Field(uint8()) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> my_iter = iter([b'\x41', b'\x42', b'\x43']) >>> preset[f1] = my_iter >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'A' >>> next(messages_gen) b'B' >>> next(messages_gen) b'C' >>> next(messages_gen) Traceback (most recent call last): ... RuntimeError: generator raised StopIteration
Fixing the value of a field, by relying on a provided function
>>> from netzob.all import * >>> f1 = Field(uint8()) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> def my_callable(): ... return random.choice([b'\x41', b'\x42', b'\x43']) >>> preset[f1] = my_callable >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'B' >>> next(messages_gen) b'C' >>> next(messages_gen) b'B'
Fixing the value of a field through its name
>>> from netzob.all import * >>> f1 = Field(uint8(), name='f1') >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> preset['f1'] = b'\x41' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'A' >>> next(messages_gen) b'A' >>> next(messages_gen) b'A'
Fixing the value of a variable leaf through its name
>>> from netzob.all import * >>> v1 = Data(uint8(), name='v1') >>> v2 = Data(uint8(), name='v2') >>> v_agg = Agg([v1, v2], name='v_agg') >>> f1 = Field(v_agg) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> preset['v1'] = b'\x41\x42\x43' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'ABC\xe9' >>> next(messages_gen) b'ABCY' >>> next(messages_gen) b'ABC\x9b'
Fixing the value of a variable node through its name
>>> from netzob.all import * >>> v1 = Data(uint8(), name='v1') >>> v2 = Data(uint8(), name='v2') >>> v_agg = Agg([v1, v2], name='v_agg') >>> f1 = Field(v_agg) >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> preset['v_agg'] = b'\x41\x42\x43' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'ABC' >>> next(messages_gen) b'ABC' >>> next(messages_gen) b'ABC'
Unfixing the value of a field
>>> from netzob.all import * >>> f1 = Field(uint8(), name='field 1') >>> symbol = Symbol([f1], name="sym") >>> preset = Preset(symbol) >>> preset[f1] = b'\x41' >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'A' >>> del preset[f1] >>> messages_gen = symbol.specialize(preset) >>> next(messages_gen) b'\xb9'
- bulk_set(items)[source]#
The
bulk_set()method inserts multiple items at once.- Parameters
items (dict, required) – the mapping to merge into the current object
Example:
>>> from netzob.all import * >>> f_data1 = Field(name="data1", domain=int8()) >>> f_data2 = Field(name="data2", domain=int8()) >>> symbol = Symbol(name="sym", fields=[f_data1, f_data2]) >>> >>> p1 = Preset(symbol) >>> presets = { ... "data1": 42, # ASCII value for '*' ... "data2": -1 ... } >>> p1.bulk_set(presets) >>> >>> next(symbol.specialize(p1)) b'*\xff'
- clear()[source]#
The
clearmethod clear the preset and fuzzing configuration.Example of clearing the Preset configuration:
>>> from netzob.all import * >>> import random >>> random.seed(0) # This is necessary only for unit test purpose >>> f_data1 = Field(name="data1", domain=int8()) >>> f_data2 = Field(name="data2", domain=int8()) >>> symbol = Symbol(name="sym", fields=[f_data1, f_data2]) >>> preset = Preset(symbol) >>> preset[f_data1] = b'\x01' >>> preset[f_data2] = b'\x02' >>> next(symbol.specialize(preset)) b'\x01\x02' >>> preset.clear() >>> next(symbol.specialize(preset)) b'EW'
- copy()[source]#
The
copymethod copies the current preset configuration.- Returns
A copy of the current preset configuration.
- Return type
Note
This method will linked the Preset configuration of the associated symbol to the new created Preset instance.
Example of copying the Preset configuration:
>>> from netzob.all import * >>> f_data1 = Field(name="data1", domain=int8()) >>> f_data2 = Field(name="data2", domain=int8()) >>> symbol = Symbol(name="sym", fields=[f_data1, f_data2]) >>> >>> preset = Preset(symbol) >>> preset[f_data1] = b'\x01' >>> preset[f_data2] = b'\x02' >>> >>> # Copy the preset configuration >>> new_preset = preset.copy() >>> >>> # Update new preset configuration >>> new_preset[f_data1] = b'\x03' >>> new_preset[f_data2] = b'\x04' >>> >>> # Generate data with the new preset configuration >>> g = symbol.specialize(new_preset) >>> next(g) b'\x03\x04' >>> >>> # Generate data with the first preset configuration >>> g = symbol.specialize(preset) >>> next(g) b'\x01\x02'
- update(new_preset)[source]#
The
updatemethod updates the current preset and fuzzing configuration with a preset configuration given in parameter. Only the configuration of the current preset is updated.- Parameters
new_preset (
Preset, required) – The preset configuration from which we want to retrieve the information.
Example of updating the Preset configuration:
>>> from netzob.all import * >>> f_data1 = Field(name="data1", domain=int8()) >>> f_data2 = Field(name="data2", domain=int8()) >>> symbol = Symbol(name="sym", fields=[f_data1, f_data2]) >>> >>> # Create main preset >>> main_preset = Preset(symbol) >>> main_preset[f_data1] = b'\x01' >>> main_preset[f_data2] = b'\x02' >>> >>> # Create new preset >>> new_preset = Preset(symbol) >>> new_preset[f_data1] = b'\x03' >>> new_preset[f_data2] = b'\x04' >>> >>> # Generate data according to the last defined preset (i.e. the 'new' preset) >>> g = symbol.specialize(new_preset) >>> next(g) b'\x03\x04' >>> >>> # Generate data according to the first defined preset (i.e. the 'main' preset) >>> g = symbol.specialize(main_preset) >>> next(g) b'\x01\x02'
Symbol with no Content#
A specific symbol may be used in the state machine to represent the absence of received symbol (EmptySymbol), when listening for incoming message, or the fact that nothing is going to be sent, when attempting to send something to the remote peer.
Relationships between Symbols and the Environment#
In the API, a memory capability is provided in order to support relationships between variables, as well as variable persistence during the specialization and abstraction processes. This capability is described in the Memory class.
- class Memory[source]#
This class provides a memory, used to store variable values (in bitarray) in a persisting and independent way.
To compute or verify the constraints and relationships that participate to the definition of the fields, the Netzob library relies on a memory. This memory stores the values of previously captured or emitted fields. More precisely, the Memory contains all the field variables that are needed according to the field definition during the abstraction and specialization processes.
Relationships between fields of successive messages
The following example shows how to define a relationship between a received message and the next message to send. A memory is used to store the value of each variable. During the first call to
specialize()on thes1symbol, the value associated to the fieldf3is notably stored in memory, so that it can be retrieved when callingspecialize()on thes2symbol. In order to create persistence for thef3field, it is mandatory to use thescopeparameter.>>> from netzob.all import * >>> f1 = Field(domain=String("hello"), name="F1") >>> f2 = Field(domain=String(";"), name="F2") >>> f3 = Field(domain=Data(String(nbChars=(5,10)), scope=Scope.MESSAGE), name="F3") >>> s1 = Symbol(fields=[f1, f2, f3], name="S1") >>> >>> f4 = Field(domain=String("master"), name="F4") >>> f5 = Field(domain=String(">"), name="F5") >>> f6 = Field(domain=Value(f3), name="F6") >>> s2 = Symbol(fields=[f4, f5, f6], name="S2") >>> >>> memory = Memory() >>> m1 = next(s1.specialize(memory=memory)) >>> m2 = next(s2.specialize(memory=memory)) >>> >>> m1[6:] == m2[7:] True
Relationships between a message field and the environment
The following example shows how to define a relationship between a message to send and an environment variable. The symbol is first defined, and then an environment variable is created. The first step consists in overloading the definition domain of the
f9field to link the environment variable.>>> from netzob.all import * >>> >>> # Symbol definition >>> f7 = Field(domain=String("master"), name="F7") >>> f8 = Field(domain=String(">"), name="F8") >>> f9 = Field(domain=String(), name="F9") >>> s3 = Symbol(fields=[f7, f8, f9]) >>> >>> # Environment variables definition >>> memory = Memory() >>> env1 = Data(String(), name="env1") >>> memory.memorize(env1, String("John").value) >>> >>> # Overloading f9 field definition to link the environment variable >>> f9.domain = Value(env1) >>> >>> # Symbol specialization >>> next(s3.specialize(memory=memory)) b'master>John'
- copy()[source]#
Copy the current memory in a new memory.
- Returns
A new memory containing the same entries as the current memory.
- Return type
>>> from netzob.all import * >>> d1 = Data(uint8()) >>> d2 = Data(String()) >>> m = Memory() >>> m.memorize(d1, uint8(100).value) >>> m.memorize(d2, String("hello").value) >>> m.getValue(d1) bitarray('01100100') >>> m2 = m.copy() >>> m2.getValue(d1) bitarray('01100100') >>> m.getValue(d1).bytereverse() >>> m.getValue(d1) bitarray('00100110') >>> m2.getValue(d1) bitarray('01100100')
- forget(variable)[source]#
Forgets any memorized value of the provided variable
- Parameters
variable (
Variable, required) – The variable for which we want to forget the value in memory.
>>> from netzob.all import * >>> variable = Data(String(), name="var1") >>> memory = Memory() >>> memory.memorize(variable, String("hello").value) >>> memory.hasValue(variable) True >>> memory.forget(variable) >>> memory.hasValue(variable) False
- getValue(variable)[source]#
Returns the value memorized for the provided variable.
- Parameters
variable (
Variable, required) – The variable for which we want to retrieve the value in memory.- Returns
The value in memory.
- Return type
bitarray
>>> from netzob.all import * >>> variable = Data(String(), name="var1") >>> memory = Memory() >>> memory.memorize(variable, String("hello").value) >>> memory.getValue(variable).tobytes() b'hello'
- hasValue(variable)[source]#
Returns true if the memory contains a value for the provided variable.
- Parameters
variable (
Variable, required) – The variable to look for in the memory.- Returns
Trueif the memory contains a value for the variable.- Return type
bool
>>> from netzob.all import * >>> variable = Data(String(), name="var1") >>> memory = Memory() >>> memory.memorize(variable, String("hello").value) >>> memory.hasValue(variable) True >>> variable2 = Data(String(), name="var2") >>> memory.hasValue(variable2) False
- memorize(variable, value)[source]#
Memorizes the provided variable value.
- Parameters
variable (
Variable, required) – The variable for which we want to memorize a value.value (
bitarrayorbytes, required) – The value to memorize.
>>> from netzob.all import * >>> variable = Data(String(), name="var1") >>> memory = Memory() >>> memory.memorize(variable, String("hello").value) >>> print(memory) Data (String(nbChars=(0,8192))) from field 'None': b'hello' >>> memory.memorize(variable, b"test") >>> print(memory) Data (String(nbChars=(0,8192))) from field 'None': b'test'
In the API, the ability to specify relationships between successive
messages or between messages and the environment is provided by the
Memory class.
Relationships between fields of successive messages
The following example shows how to define a relationship between a
received message and the next message to send. A memory is used to store the value of each variable. During the first call to specialize() on the s1 symbol, the value associated to the field f3 is notably stored in memory, so that it can be retrieved when calling specialize() on the s2 symbol:
>>> from netzob.all import *
>>> f1 = Field(domain=String("hello"), name="F1")
>>> f2 = Field(domain=String(";"), name="F2")
>>> f3 = Field(domain=String(nbChars=(5,10)), name="F3")
>>> s1 = Symbol(fields=[f1, f2, f3], name="S1")
>>>
>>> f4 = Field(domain=String("master"), name="F4")
>>> f5 = Field(domain=String(">"), name="F5")
>>> f6 = Field(domain=Value(f3), name="F6")
>>> s2 = Symbol(fields=[f4, f5, f6])
>>>
>>> memory = Memory()
>>> m1 = next(s1.specialize(memory=memory))
>>> m2 = next(s2.specialize(memory=memory))
>>>
>>> m1[len("hello;"):] == m2[len("master>"):]
True
Relationships between a message field and the environment
The following example shows how to define a relationship between a
message to send and an environment variable. The symbol is first
defined, and then an environment variable is created. The first step
consists in overloading the definition domain of the f9 field to
link the environment variable:
>>> from netzob.all import *
>>>
>>> # Symbol definition
>>> f7 = Field(domain=String("master"), name="F7")
>>> f8 = Field(domain=String(">"), name="F8")
>>> f9 = Field(domain=String(), name="F9")
>>> s3 = Symbol(fields=[f7, f8, f9])
>>>
>>> # Environment variables definition
>>> memory = Memory()
>>> env1 = Data(String(), name="env1")
>>> memory.memorize(env1, String("John").value)
>>>
>>> # Overloading f9 field definition to link the environment variable
>>> f9.domain = Value(env1)
>>>
>>> # Symbol specialization
>>> next(s3.specialize(memory=memory))
b'master>John'
Persistence during Specialization and Abstraction of Symbols#
The values of variables defined in fields can have different assignment strategies, depending on their persistence and lifecycle.
The Scope class provides a description of those strategies, along with some examples.
- class Scope(value)[source]#
This class represents the Assignment Strategy of a variable.
The scope of a variable defines how its value is used while abstracting and specializing, and therefore impacts the memorization strategy.
A scope strategy can be attached to a variable and is used both when abstracting and specializing. A scope strategy describes the set of memory operations that must be performed each time a variable is abstracted or specialized. These operations can be separated into two groups: those used during the abstraction and those used during the specialization.
The available scope strategies for a variable are:
Scope.SESSION
Scope.MESSAGE
Scope.NONE (the default strategy for variables)
Those strategies are explained below. In addition, some following examples are shown in order to understand how the strategies can be applied during abstraction and specialization of Field with Data variables.
Scope.SESSION: This kind of variable carries a value, such as a session identifier, generated and memorized during its first specialization and reused as such in the remainder of the session. Conversely, the first time a Session Scope field is abstracted, the value of its variable is not defined and the received value is saved. Later in the session, if this field is abstracted again, the corresponding variable is then defined and we compare the received field value against the memorized one.
The following example shows the abstraction and specialization of data with Session Scope:
>>> from netzob.all import * >>> f = Field(domain=Data(String(nbChars=4), scope=Scope.SESSION), name='f1') >>> s = Symbol(name="S0", fields=[f]) >>> m = Memory() >>> next(s.specialize(memory=m)) b'SZ,1' >>> s.abstract(b'SZ,1', memory=m) OrderedDict([('f1', b'SZ,1')]) >>> next(s.specialize(memory=m)) b'SZ,1' >>> s.abstract(b'test', memory=m) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.AbstractionException: With the symbol/field 'S0', cannot abstract the data: 'b'test''. Error: 'No parsing path returned while parsing 'b'test'''
>>> from netzob.all import * >>> f = Field(domain=Data(String(nbChars=4), scope=Scope.SESSION), name='f1') >>> s = Symbol(name="S0", fields=[f]) >>> m = Memory() >>> s.abstract("john", memory=m) OrderedDict([('f1', b'john')]) >>> next(s.specialize(memory=m)) b'john' >>> s.abstract("john", memory=m) OrderedDict([('f1', b'john')]) >>> s.abstract(b'test', memory=m) Traceback (most recent call last): ... netzob.Model.Vocabulary.AbstractField.AbstractionException: With the symbol/field 'S0', cannot abstract the data: 'b'test''. Error: 'No parsing path returned while parsing 'b'test'''
Scope.MESSAGE: With this kind of variable, the value is generated and then memorized during the first specialization and is always memorized during abstraction. For further specialization, the value is taken from memory. However, in contrary to the Session Scope, no comparison is made during abstraction with the current memorized value (i.e. the received value is always memorized). For example, the IRC nick command corresponds to a Message Scope, that denotes the new nick name of the user. This nick name can afterwards be used in other fields, but whenever a NICK command is emitted, its value is regenerated.
The following example shows the abstraction and specialization of data with Message Scope:
>>> from netzob.all import * >>> f = Field(domain=Data(String(nbChars=4), scope=Scope.MESSAGE), name='f1') >>> s = Symbol(name="S0", fields=[f]) >>> m = Memory() >>> next(s.specialize(memory=m)) b'X!z@' >>> s.abstract("john", memory=m) OrderedDict([('f1', b'john')]) >>> next(s.specialize(memory=m)) b'john' >>> next(s.specialize(memory=m)) b'john'
>>> from netzob.all import * >>> f = Field(domain=Data(String(nbChars=4), scope=Scope.MESSAGE), name='f1') >>> s = Symbol(name="S0", fields=[f]) >>> m = Memory() >>> s.abstract("john", memory=m) OrderedDict([('f1', b'john')]) >>> next(s.specialize(memory=m)) b'john' >>> s.abstract("kurt", memory=m) OrderedDict([('f1', b'kurt')]) >>> next(s.specialize(memory=m)) b'kurt'
Scope.NONE: This kind of variable denotes a value which changes whenever it is specialized and is never memorized. The abstraction process of such a field only verifies that the received value complies with the field definition domain without memorizing it. For example, a size field or a CRC field should have such a scope.
The following example shows the abstraction and specializaion of data without persistence:
>>> from netzob.all import * >>> f = Field(domain=Data(String(nbChars=4), scope=Scope.NONE), name='f1') >>> s = Symbol(name="S0", fields=[f]) >>> m = Memory() >>> next(s.specialize(memory=m)) b'4%!F' >>> s.abstract("john", memory=m) OrderedDict([('f1', b'john')]) >>> next(s.specialize(memory=m)) b'v\tK5'
>>> from netzob.all import * >>> f = Field(domain=Data(String(nbChars=4), scope=Scope.NONE), name='f1') >>> s = Symbol(name="S0", fields=[f]) >>> m = Memory() >>> s.abstract("john", memory=m) OrderedDict([('f1', b'john')]) >>> next(s.specialize(memory=m)) b'h:JM' >>> s.abstract("kurt", memory=m) OrderedDict([('f1', b'kurt')])